Summary: message queueing with RabbitMQ helps software applications connect and scale, by enabling messaging patterns like data delivery, push notifications, publish/subscribe, and text messages. It can be easily implemented in Ruby.
Background
If you’re already familiar with message queueing, or if you’re someone who doesn’t like reading the instructions, jump to the code section below.
Definition of terms
I recently came across some brand new terms. So, to begin, some definitions via Wikipedia (they may still be confusing; I try to clear them up below):
- Advanced Message Queuing Protocol (AMQP): an open standard application layer protocol for message-oriented middleware. The defining features of AMQP are message orientation, queuing, routing (including point-to-point and publish-and-subscribe), reliability and security.
- Message-oriented middleware: Message-oriented middleware (MOM) is software or hardware infrastructure supporting sending and receiving messages between distributed systems.
- Distributed system: A distributed system is a software system in which components communicate and coordinate their actions by passing messages.
The underlined terms demonstrate that you can’t understand AMQP without understanding MOM, which depends on an understanding of distributed systems, which takes you back to passing messages. Kinda circular. Perhaps some further reading will help:
Modern web-scale applications like Google, Twitter, Netflix, LinkedIn, etc. are implemented as distributed systems as opposed to single monolithic codebases. This means that they are composed of tens or hundreds of services that communicate asynchronously with each other, ultimately delivering a response to the end-user.
This means that, for most web development purposes, “distributed systems” can be replaced with “web apps” in our definition of message-oriented middleware. Furthermore:
One common simplification I see engineers make is equating message queueing with background processing. […] All message processing is done in the background but background processing does not have to be done via message queues.
This is actually really helpful. Message queing (of which AMQP is one protocol) is a subset of background processes. [Side note: This quote comes from the creator of Sidekiq, a popular handler of background processes for Ruby. He knows a thing or two about this stuff.] With that in mind, we can understand AMQP as a background process specifically for message queueing.
Use cases
So what is AMQP actually used for? RabbitMQ describes that:
Messaging enables software applications to connect and scale. Applications can connect to each other, as components of a larger application, or to user devices and data. Messaging is asynchronous, decoupling applications by separating sending and receiving data.
For example, MercadoLibre.com, the biggest e-commerce site in Latin America, uses AMQP to send messages for new listings, seller updates, bids placed, and more:
…every time there is a new listing on the platform, a seller updates an item, a bid is placed, or whatever event that could affect the representation of the data, a message is sent through RabbitMQ so each consumer is aware of the news and reacts properly to the event.”
Code Examples
I followed this guide, using the Bunny gem, to get started with RabbitMQ.
The basics
Start by installing RabbitMQ with Homebrew:
brew install rabbitmq
Then start the server:
rabbitmq-server
A simple example
The code snippet below demonstrates a simple example. One application (in line 25) publishes a message that ends up in a queue (declared in line 14) for the second application (lines 20-22) to listen to.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
The comments in the snippet explain what’s happening at each step. We connect to RabbitMQ and open a new channel, then declare a queue and instantiate an exchange, so that when x.publishes that message and routes it to q (the queue), that payload goes through.
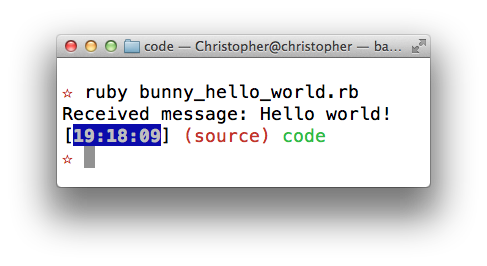 And the contrived example works, when I run the code:
And the contrived example works, when I run the code:
The image below may help make sense of the routing. Or maybe a more complicated example will.
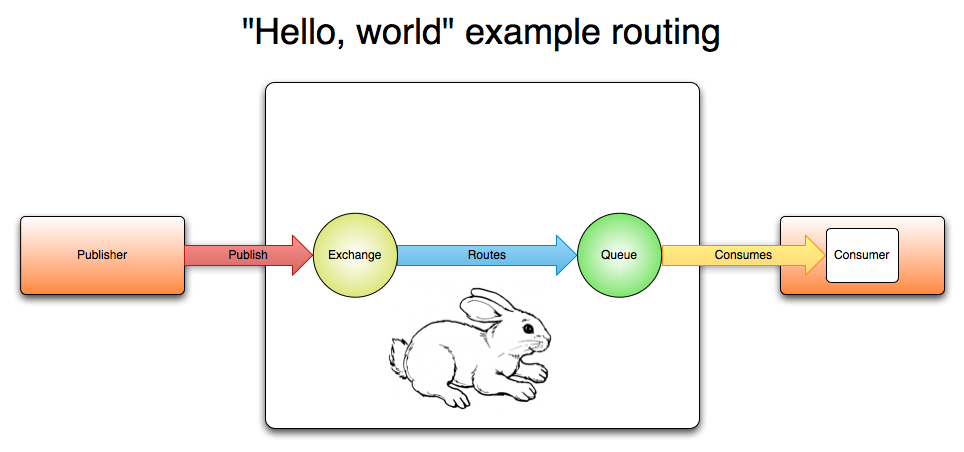
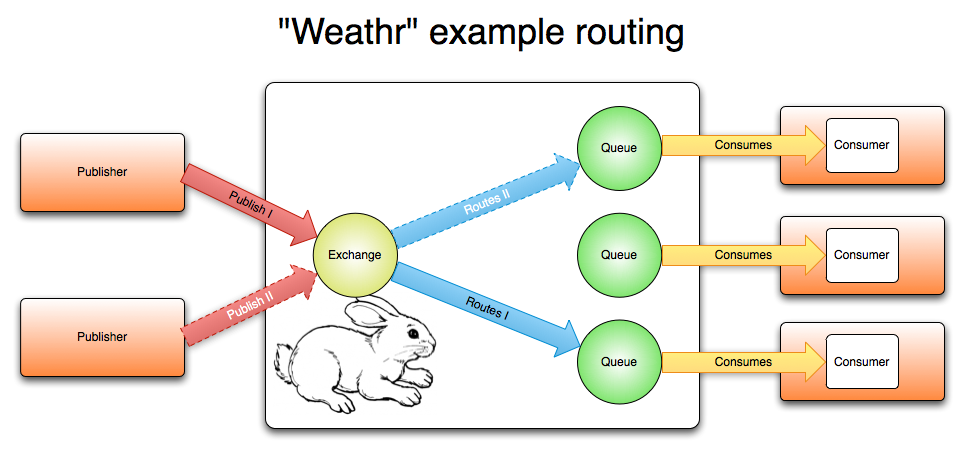
A more complicated example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | |
It again works when I run the code:
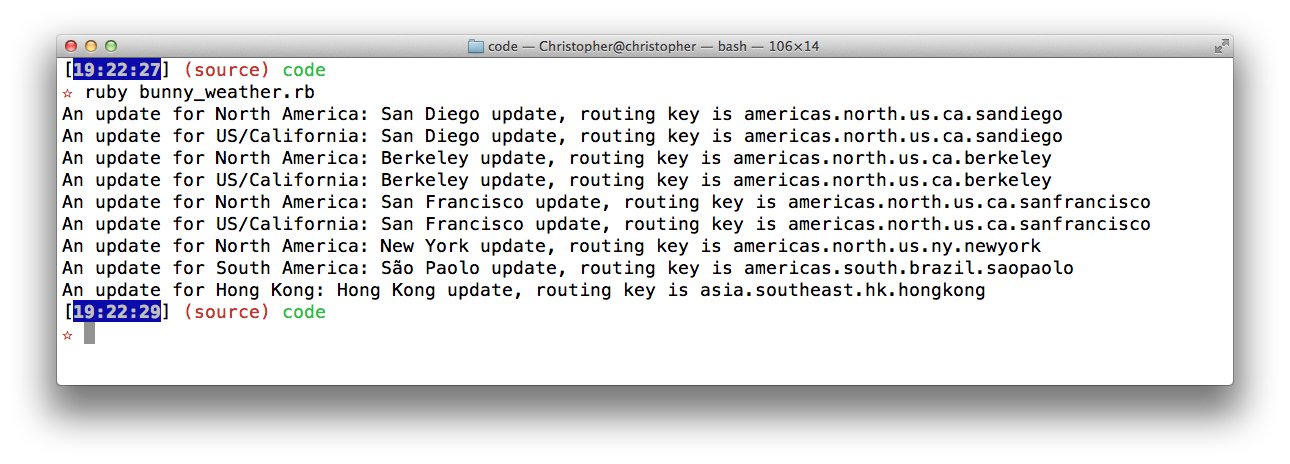
Notice that there were as many deliveries as there were subscribers (9), and that the order was determined by the order of published updates.
The end
From what I’m told, “this is only the tip of the iceberg” and there are many more features including:
- Reliable delivery of messages
- Message confirmations (a way to tell broker that a message was or was not processed successfully)
- Message redelivery when consumer applications fail or crash
- Load balancing of messages between multiple consumers
- Message metadata attributes
- High availability features