<![CDATA[CEK.io]]>2019-06-27T15:15:02+01:00http://cek.io/Octopress<![CDATA[A (Scheme) Calculator in Clojure]]>2019-06-27T11:30:00+01:00http://cek.io/blog/2019/06/27/scheme-clojure-calculatorI’ve been working through Structure and Interpretation of Computer Programs (SICP) and watching the UC Berkeley CS61A lectures from Brian Harvey. It’s great content, so I can understand why he refers to SICP as “the best computer science book in the world”.
The most recent lecture presented a calculator implementation (for a calculator with four functions) in Scheme. This calculator is a simple REPL interpreter: it reads a user input, evaluates it, prints the output, and loops back again.
What follows is a summary of the lecture with my takeaways, including a description of the program (and why it’s worth considering), the original Scheme program from the lecture, and my translation of it into Clojure.
Why look at this example?
There are two main reasons to look at this:
It is an example of processing deep lists (lists of lists of lists)
This is a step towards understanding an actual Scheme interpreter written in Scheme. Unlike an actual Scheme interpreter, this has no variables and no procedures as first-class things. It only has four procedures: +, /, -, and *. But it’s Scheme-like in its notation ((+ 6 7)) and does composition of functions as Scheme does.
The 4-function calculator code
Original Scheme code:
123456789101112131415161718192021
(define (calc)(display "calc: ")(flush)(print(calc-eval(read)))(calc))(define (calc-evalexp)(cond ((number? exp)exp)((list? exp)(calc-apply(car exp)(map calc-eval(cdr exp))))(else (error"Calc: bad expression:"exp))))(define (calc-applyfnargs)(cond ((eq? fn'+)(accumulate+0args))((eq? fn'-)(cond ((null? args)(error"Calc: no args to -"))((= (length args)1)(- (car args)))(else (- (car args)(accumulate+0(cdr args))))))((eq? fn'*)(accumulate*1args))((eq? fn'/)(cond ((null? args)(error"Calc: no args to /"))((= (length args)1)(/ (car args)))(else (/ (car args)(accumulate*1(cdr args))))))(else (error"Calc: bad operator:"fn))))
And my translation into Clojure:
12345678910111213141516171819202122232425
(defn calc-apply[fn args](cond(= fn '+)(reduce + 0args)(= fn '-)(cond(nil? args)(throw(Exception."Calc: no args to -"))(= (count args)1)(- (first args)):else(- (first args)(reduce + 0(rest args))))(= fn '*)(reduce * 1args)(= fn '/)(cond(nil? args)(throw(Exception."Calc: no args to /"))(= (count args)1)(/ (first args)):else(/ (first args)(reduce + 0(rest args)))):else(throw(Exception.(str "Calc: bad operator:"fn)))))(defn calc-eval[exp](cond(number?exp)exp(list?exp)(calc-apply(first exp)(map calc-eval(rest exp))):else(throw(Exception.(str "Calc: bad expression:"exp)))))(defn calc[](println "calc: ")(println (calc-eval(read)))(calc))
Dealing with Deep Lists
The key to handling deep lists can be seen in (map calc-eval (cdr exp)). It is sort of a recursive call, but not a exactly a recursive call, because there’s no open parenthesis in front of calc-eval. Instead, calc-eval is an argument to map; map will typically call calc-eval more than once (for each sub-expression). So it’s not just a simple recursive call, but a multi-way recursive call, which is the secret of dealing with deep lists.
For deep lists, we make a recursive call for each element of the top level list, and then for each element of sub-lists, and so on all the way down. The base case is an empty list (or when the expression isn’t a list).
Interpreters and Types of Expressions
There are three pieces to an interpreter (and this goes for any interpreter, not just Scheme or Clojure):
The read-eval-print loop (REPL). It’s a loop because the last thing in it is a call to itself, so it runs forever. In the example, read turns things in parentheses into pairs. calc-eval takes an expression as its argument and returns (and prints) the value of that expression.
(eval exp) returns the value of the expression
(apply function arglist) returns the value returned by the function. This is where the example is different from a full interpreter: the actual Scheme interpreter handles first-class procedures, whereas this calculator example depends on the name of the function (must be one of +, /, -, and *.
In Scheme, there are basically four types of expressions:
Self-evaluating expressions (primitives) like numbers or booleans — these are used in the calculator
Variables — these are not supported in the calculator
Function calls — these are used in the calculator
Special forms — these are not supported in the calculator. A full interpreter would include special forms, but this introduces a lot of complexity which is ignored in the calculator example.
In an interpreter, an evaluator’s job is to take the stuff that is typed in and figure out what it means. This requires figuring out what the notation means. Scheme and Clojure (or any Lisp) make this easier, because a complete expression is one list; the language was designed in order to be able to evaluate its own programs. Compare this to Java, for example, where there are many different notations that are not uniform, so what you can put in one context is different than another context.
Lispians say “at the heart of every programming language there’s a lisp interpreter trying to get out”, because you have to evaluate expressions that are procedure calls. Syntax doesn’t get in the way.
A few differences between a full interpreter and this example can be seen in the following:
calc-eval: we will not see a recursive call for (car exp) in calc-eval; (car exp) has to be one of the 4 math symbols, but in a real Scheme interpreter it could be a symbol that’s the name of a procedure, or it could be a lambda or procedure call or any number of other things to provide the function (so it would need to be evaluated).
calc-apply: this function takes fn and args as its arguments, where args is always a list. This is not just a simplification, but an actual difference from a full interpreter: we don’t have procedures as first-class values, so fn argument is a symbol, not the procedure itself. This means that the calculator cannot handle all procedures (like sqrt, etc.)
There are a number of properties of a programming language that determine what it is to be a program in that language. For example, Scheme has first-class procedures, applicative order, variables. All of these properties manifest themselves in the interpreter; we can look at the interpreter and ask “how would I change this interpreter if I wanted Scheme, but with normal order instead of applicative order?” In that case, don’t call (map calc-eval (cdr exp)), but just use (cdr exp). Then we’d be giving apply actual argument expressions rather than argument values.
Syntax and Semantics
Syntax is the technical term for the form of a program, what the program looks like. The Scheme function syntax is (procedure arg arg arg). Semantics is what that thing means. For example, (procedure arg arg arg) means “call that procedure with these argument values after you’ve recursively evaluated the argument expressions”. There are differences across languages, but we see more or less the same kinds of things in the semantics—conditionals, loops, call functions, define variables—while syntax can be very different across languages.
An important point about the calculator: we are actually dealing with two different programming languages. The calculator is a program written in Scheme, but the language that the calculator implements is a programming language that isn’t Scheme. For example, there are no variables in this calculator programming language. When Scheme interpreters are written in Scheme, there are also two languages involved (and it’s more difficult to see the differences than Scheme vs. calculator language).
Notice that eval lives in both the syntax and semantics worlds. When it takes an expression (syntax) and returns a value, it turns syntax into semantics by turning the form into something meaningful. Meanwhile apply doesn’t know anything about syntax. It takes a procedure and argument values, so it’s entirely about semantics.
An Aside on Functional Programming
The read and print functions are primitive procedures that are not functional. read is not functional because, every time you call it with the same arguments, you get a different answer. print is not functional because it changes the state of the world. Functions just compute and return values. Even though Scheme is a functional programming language, the Scheme interpreter itself is not an entirely functional program. Most of it (eval and apply) is functional, since it just takes arguments and returns values.
Some Clojure/Scheme Observations
Clearly Scheme and Clojure are both Lisps. It’s nice to see that the Clojure implementation is as consise as Scheme (it’s four more lines, but that could be eliminated if we didn’t put the four conds on their own line). There are a few syntax differences (Clojure reduce instead of Scheme accumulate, read-line instead of read), but the semantics are identical.
One final syntax difference: In Scheme (and Common Lisp and most other Lisp dialects), cons is a primitive data structure made up of a pair. In Clojure, this is not the case. We can see the cons in the Scheme example when we use car (to access the first element) and cdr (to access the rest). Clojure does have a cons function, but it works differently:
1234567
(cons 12); IllegalArgumentException Don't know how to create ISeq from: java.lang.Long(cons 1'(234)); (1 2 3 4); this is not a list, but a Cons(list?(cons 1'(234))); false(type(cons 1'(234))); clojure.lang.Cons
This is really a subject for furtherreading, but suffice it to say that Clojure is a Lisp with some differences from other Lisps, including the fact that “cons, first and rest manipulate sequence abstractions, not concrete cons cells”.
]]><![CDATA[A Clojure Introduction to Binary and Bitwise Operators]]>2017-08-17T23:00:00+01:00http://cek.io/blog/2017/08/17/clojure-introduction-binary-bitwiseI’ve been working in Clojure and ClojureScript lately. A few months back, I came across this one weird trick to master Clojure. TL;DR: it recommends reading the API docs, fully, top to bottom.
I’m not even joking! Go to this URL http://clojure.github.io/clojure/clojure.core-api.html and start reading from top to bottom. If you did not read through that page, you may not know about amap. If you stopped reading before you get to ‘f’ you wouldn’t know about frequencies. However, if you read all the way through, you will be rewarded with knowledge about vary-meta.
In the process of doing this, I was struck by all the bit- functions — of the ~600 vars and functions in clojure.core, there are 12 specifically for bitwise operations.
We can disregard leading zeros in binary, so binary 0010 and binary 10 both represent decimal 2.
Each position is one bit (“bit” means “binary digit”). So 1111 is a 4-bit integer (so we can represent up to 15 different values). A 32-bit integer maxes at 11111111111111111111111111111111 (so we can represent up to 4,294,967,295 values). We’ll see that we don’t always use every position counting up from 0 (the left-most position will be used to determine positive/negative).
This blog post uses 2r.... and Integer/toBinaryString to convert between binary and decimal. Other functions and formatters are discussed here.
Bitwise Operators
This brings us to the bitwise operators. There are 12 in clojure.core (all visible in the source):
bit-and – Bitwise and
12345678910111213
;; `bit-and` does a logical AND across columns;; 1010 ; 10;; 1001 ; 9;; ----;; 1000 ; 8 ; by column: 1 AND 1 => 1;; 0 AND 0 => 0;; 1 AND 0 => 0;; 0 AND 1 => 0user=>(bit-and 109)8user=>(bit-and 2r10102r1001)8
bit-or – Bitwise or
12345678910111213
;; `bit-or` does a logical OR across columns;; 1010 ; 10;; 1001 ; 9;; ----;; 1011 ; 11 ; by column: 1 OR 1 => 1;; 0 OR 0 => 0;; 1 OR 0 => 1;; 0 OR 1 => 1user=>(bit-or 109)11user=>(bit-or 2r10102r1001)11
bit-xor – Bitwise exclusive or
12345678910111213
;; `bit-xor` does an exclusive OR across columns (true when the two values are different);; 1010 ; 10;; 1001 ; 9;; ----;; 0011 ; 11 ; by column: 1 XOR 1 => 0;; 0 XOR 0 => 0;; 1 XOR 0 => 1;; 0 XOR 1 => 1user=>(bit-xor 109)3user=>(bit-xor 2r10102r1001)3
bit-not – Bitwise complement
123456
;; `bit-not` does a complement, negating each position so each 0 becomes 1 and each 1 becomes 0;; this reads 1010 as the 32-bit integer 00000000000000000000000000001010 (including leading 0s),;; which, when negated/complemented, becomes 11111111111111111111111111110101 (represents decimal -11).user=>(bit-not 2r1010)-11
bit-and-not – Bitwise and with complement
123456789
;; `bit-and-not` ANDs the first integer with the complement of the second;; (bit-and-not 2r1010 2r1001);; (bit-and 2r1010 (bit-not 2r1001));; (bit-and 2r1010 2r0110) => 0010 => 2user=>(bit-and-not2r10102r1001)2user=>(bit-and 2r1010(bit-not 2r1001))2
bit-clear – Clear bit at index n
12345678910
;; `bit-clear` sets the bit to 0 at a given index (0-based, right to left)user=>(bit-clear2r10110);; clears the 0th bit from right10;; 2r1010user=>(bit-clear2r10111);; clears the 1st bit from right9;; 2r1001user=>(bit-clear2r10112);; clears the 2nd bit from right11;; 2r1011user=>(bit-clear2r10113);; clears the 3rd bit from right3;; 2r0011
bit-flip – Flip bit at index n
12345678910
;; `bit-flip` flips the bit (changes 0 to 1 or 1 to 0)at a given indexuser=>(bit-flip2r10100);; flips the 0th bit from right11;; 2r1011user=>(bit-flip2r10101);; flips the 1st bit from right8;; 2r1000user=>(bit-flip2r10102);; flips the 2nd bit from right14;; 2r1110user=>(bit-flip2r10103);; flips the 3rd bit from right2;; 2r0010
bit-set – Set bit at index n
1234
;; `bit-set` sets the bit to 1 at a given indexuser=>(bit-set2r10102);; sets the 2nd bit from right to 114;; 2r1110
bit-test – Test bit at index n
1234
user=>(bit-test2r10100);; checks if the 0th bit from right is 1falseuser=>(bit-test2r10101);; checks if the 1st bit from right is 1true
bit-shift-left – Bitwise shift left
123456
;; `bit-shift-left` shifts the entire integer left, filling in empty spaces as 0user=>(bit-shift-left 2r10101);; shifts the integer left 1 position (filling empty position with 0)20; 2r10100user=>(bit-shift-left 2r10113);; shifts the integer left 3 positions (filling empty positions with 0)88; 2r1011000
bit-shift-right – Bitwise shift right
123456
;; `bit-shift-right` shifts the entire integer right, clearing positions < 0user=>(bit-shift-right 2r10101);; shifts the integer right 1 position5; 2r101user=>(bit-shift-right 2r10113);; shifts the integer right 3 positions1; 2r1
unsigned-bit-shift-right – Bitwise shift right, without sign-extension
12345678
;; `unsigned-bit-shift-right` does a `bit-shift-right` (so same behavior for small integers). its;; difference is that all the other operations are for 32-bit signed integers, whereas this accepts;; unsigned (no negative values, only positive) integersuser=>(unsigned-bit-shift-right2r10101)5user=>(bit-shift-right 2r10101)5
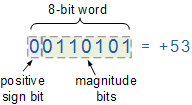
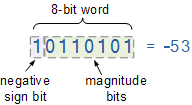
Negative numbers can be represented using signed integers, where the left-most position represents whether the integer is positive or negative. In one implementation (sign-magnitude notation), the left-most bit is the sign, and the remaining bits are the value.
This means that in an n-bit integer (e.g., 4-bit), the left-most bit signifies positive/negative, so the remaining n-1 (3) bits can hold the actual value. There are 16 possible values for a 4-bit integer (0000 to 1111), meaning that a signed 4-bit integer can go from -7 to +7 (it is 16 possible values because we can represent both -0 and +0, as binary 1000 and 0000).
Two’s Complement
Two’s Complement is a slightly more complicated scheme for signed integers (though not overly so), and the one more commonly used. A leading 1 still signifies a negative integer. The difference is that it’s not simply sign (1st bit) and magnitude (remaining bits), because the magnitude is determined using the complement (hence the name).
Up until now, all the code samples have been unsigned integers, which is why all the values are positive (and all the examples with a leading 1 haven’t been negative). Assuming 8-bit signed integers, we interpret things as follows:
1234567
00001010;; 10;; to get -10, complement and add 111110101;; first complement11110110;; then add 1;; so 11110110 is the signed 8-bit representation of -10
Idiosyncracies between signed and unsigned integers
I alluded to this in the previous section: all the code samples have been unsigned integers. We’ve been exploring conversions between decimal and binary using Clojure’s radix-based entry format (e.g., 2r1010), which uses Java Longs and Java’s Integer/toBinaryString, which returns strings.
I say there appear to be inconsistencies, because this is the expected result of using Long. A full discussion gets into the intricacies of language design and primitives, as exemplified by threads like this and this.
<![CDATA[Ramda.js Array Sorting (With Tiebreakers) Using R.comparator, Variadic R.either, and R.reduce]]>2016-10-29T17:50:14+01:00http://cek.io/blog/2016/10/29/ramda-sort-tiebreakers-comparators-eitherA recent exercise in data processing with Ramda.js: I wanted to sort an array of objects by their key/value pairs. More specifically, I wanted to sort an array that looked like this:
How can we handle tiebreakers? That is, as in the example abolve, what if two elements in the array have identical gold values and we attempt to sort by gold — which should be sorted first? We can ensure a deterministic result with predictable tiebreaks using comparators and R.either.
R.comparator enforces descending order and second R.comparator passed to R.either breaks ties
Finally, what if we need more than one tiebreaker? How do we handle objects that have identical gold AND silver values? R.either expects two arguments, so the solution is to create a variadic implementation of R.either, one that will accept an unknown number of arguments, so we can pass tiebreaker comparators for all possible situations:
Addresses all edge cases: sort by gold; if gold ties sort by silver; if silver ties sort by bronze; if bronze ties sort by country code
12345678
constvariadicEither=(head,...tail)=>R.reduce(R.either,head,tail);constgoldComparator=R.comparator((a,b)=>R.gt(R.prop('gold',a),R.prop('gold',b)));constsilverComparator=R.comparator((a,b)=>R.gt(R.prop('silver',a),R.prop('silver',b)));constbronzeComparator=R.comparator((a,b)=>R.gt(R.prop('bronze',a),R.prop('bronze',b)));constcodeComparator=R.comparator((a,b)=>R.lt(R.prop('code',a),R.prop('code',b)));// sorts alphabetically by country codeR.sort(variadicEither([goldComparator,silverComparator,bronzeComparator,codeComparator]),array);
The crux of this solution is variadicEither, a variadic re-implementation of R.either that can accept a variable number of arguments. It uses head (first argument) and ...tail (all remaining arguments) to reduce over all arguments and return a function that addresses all tiebreak possibilities. R.sort expects a comparator function, which R.either and variadicEither both return.
Of course this solution still has a bit of boilerplate (repetition of R.comparator(...)). For a reusable sortByProps implementation that takes an array of props and a list, see this Ramda.js recipe that I recently added.
]]><![CDATA[Knexfile Configuration for Heroku Deployment]]>2016-10-24T14:29:50+01:00http://cek.io/blog/2016/10/24/knex-configuration-herokuI recently deployed a simple Express server to Heroku. The project used Knex.js for SQL queries and database migrations.
While deploying, I ran into some issues with my knexfile. That is, I was able to create the database using the Heroku CLI, but running the migrations and configuring the database connection took a bit of finessing.
Long story short, two parts:
1. Database URL (Connection)
Find your database url. Using Heroku CLI, running heroku config (or heroku config --app [app name]) will return something like the following:
]]><![CDATA[D3 and React Faux DOM]]>2016-07-07T00:56:50+01:00http://cek.io/blog/2016/07/07/d3-and-react-faux-domAuthor’s Note: This post makes my original post exploring React + D3 obselete. I strongly recommend react-faux-dom (on Github) over my previous post’s suggestion.
TL;DR, Hear it straight from the lib author: Oliver Caldwell wrote this blog post about react-faux-dom, which enables a cleanly organized and powerful combination of React and D3.
That post in four bullet points:
D3 works by mutating the DOM. Select a DOM element, append children, etc.
React works by reconciling the DOM. Build a tree, compare to DOM, determine which elements to add/remove/change.
DOM mutation (like D3 does) and DOM reconciliation (like React does) don’t work together so well.
react-faux-dom makes a fake DOM to support D3. It might seem silly, but it enables us to support D3 while remaining within React.
Using a fake DOM means we can drop D3 scripts into a React component’s render() function and it’ll just work. It was trivial to prove out in a production PR:
Rendering a sparkline is as simple as <Sparkline width={500} height={500} max={10} data={[1, 3, 2, 5, 4]} interpolation={"basis"} />. We get the benefits of React semantics AND the D3 API, both neatly organized in their respective places.
I consider it a clear win to maintain React component organization while leveraging the power of all that D3 offers, but I suppose what it comes down to is this:
For me, it's about worrying about the right "lines" to draw in your app, then fill the few shapes those lines create with garbage and ship.
So many code design decisions boil down to the border between things. The interface. The “line” between where React component code belongs and where D3 code belongs. Ultimately, this still leaves us to fill in the lines with whatever we choose to write, but this library’s placement of the “line” is an improvement over anything else I’ve seen.
As the author writes, “All [React and D3] concepts remain the same, react-faux-dom is just the glue in the middle.” This clean separation is hugely helpful in writing dataviz React components with D3.
]]><![CDATA[A Single Set of Color Vars With PostCSS]]>2016-06-30T13:05:35+01:00http://cek.io/blog/2016/06/30/postcss-color-varsIn this post, I describe how to create a single list of color variables (in JavaScript) so that those colors can be shared across JavaScript files and CSS stylesheets. Using PostCSS within a Webpack app, I outline the problem of sharing styles between CSS and JS and how it can be solved. For step-by-step code examples, skip ahead to “Enter PostCSS (Problem Solved)”.
The Problem We’re Solving
At my day job, we’d had a colors.css file for a while, where we define all the hex codes for our color scheme, as defined by our designers. It looked something like this:
Straightforward, keeps things DRY, makes it easy to change colors when it strikes the designer’s fancy, etc.
For a long time, while our CSS colors were nicely organized, our JS colors weren’t. We have colors in our D3 visualizations and our inline styles on React components. As a simple improvement, I decided to pull all our colors into a single map that could be read by both our CSS and JS files. NB: this post is about CSS colors, but can apply to any CSS variables you’d like shared to JS.
Since I had previously been using cssnext, I followed [these migration steps](http://cssnext.io/postcss/#postcss-loader) to upgrade to postcss-cssnext. This meant swapping the `cssnext-loader` for `postcss-loader` in my Webpack loaders, removing cssnext from my webpack config, and adding the postcss options to webpack config:
module.exports={module:{loaders:[{test:/\.css$/,loader:"style-loader!css-loader!postcss-loader"}]},postcss:function(webpack){return[require("postcss-import")({addDependencyTo:webpack}),require("postcss-url")(),require("postcss-cssnext")({features:{customProperties:{variables:colorVars// `colorVars` will be defined above, see step 4.}}}),require("postcss-browser-reporter")(),require("postcss-reporter")(),]},}
Add a colors.js. I chose to CONSTANT_CASE the variables (for idiomatic JS).
// to be added aboce `module.exports` of webpack.config.jsvarcolorVars=require("./app/constants/colors")
(OPTIONAL) Because I wanted CSS variables to be lowercase and hyphen-separated so I could maintain our old `color: var(–light-grey);` syntax, I added a transformation from the constant case (using Ramda’s `curry` and `reduce`):
// to be added above `module.exports` of webpack.config.js// color vars in JS are CONST_CASE, but need to be converted to hyphen-case for CSSconstrenameKeys=R.curry((renameFn,obj)=>{returnR.reduce((acc,key)=>{acc[renameFn(key)]=obj[key]returnacc},{},R.keys(obj))})constconstCaseToHyphenCase=(str)=>{returnstr.replace(/_/g,"-").toLowerCase()}varcolorVars=renameKeys(constCaseToHyphenCase,require("./app/constants/colors"))
// we can now do this in React components or any other JS filevarcolors=require("app/constants/colors")// ...render(){return<divstyle={{backgroundColor:colors.white}}/>}
/* and this still works, without even needing to `@import "../theme/colors";` */.my-special-component{background-color:var(--white);color:var(--red);}
And that’s it! Now, in addition to everything it already did, running webpack-dev-server will (1) compile using PostCSS, (2) read from colors.js, and (3) set all colors in colors.js as global CSS variables.
Limitations
The one limitation is hot-reloading. That is, hot reloading works perfectly on changes to JavaScript files and CSS files, with one exception: colors.js. Since colors.js is read on build, we need to restart the webpack dev server anytime we change or add a color variable. This question poses effectively the same issue (“…every time I change a variable I have to restart the webpack dev server”). For now, that’s a tradeoff I can live with.
Parting thoughts
This new pattern enables much more inline styling with JavaScript. That is, now our React components and D3 visualizations can, in theory, read style variables from JavaScript and never know about CSS.
Following this to its extreme of no-CSS/all-JS may seem crazy, but I remain curious. A lothas beensaid about how inline styles with JavaScript may be the future. At a minimum, it’s convenient and fun to do more JS and less CSS. I’m excited to see how the community experiments with inline styling and if there come to be best practices around separation of concerns.
]]><![CDATA[React Conf Reactions]]>2016-02-27T21:43:32+00:00http://cek.io/blog/2016/02/27/react-confThe React.js Conf was a blast. All the talks were recorded and can be watched here. My full bullet point notes are here, but what follows are some more readable reactions to the conference.
First of all, a special thanks to the organizers and speakers. This was a very well run conference with some high-class talks. From breakfast Monday through to the closing reception on Tuesday, with the single exception of jackhammer noises during some of the talks (what are you gonna do about construction next door?), everything was very well done.
Moving on, I learned a ton, got to know some awesome members of this community, and met some incredible people who’ve influenced my career (by giving talks, authoring open-source, or otherwise helping me write better code). Here’s a couple of my main takeaways, in no particular order.
I came into the conference with React.js and Redux experience, but little to no knowledge of GraphQL, Relay, or React Native. I was not disappointed then, that the majority (maybe two-thirds?) of the talks addressed exactly those things. For a long time, React Native has been on my list of new tech to explore, as someone who’s never written anything for mobile. GraphQL and Relay, meanwhile, could be directly applicable to my everyday work. And I’m of course always pleased to learn new things about what I already “know”, like aspects of React performance that I haven’t thought about.
If the majority of the talks addressed React.js, React Native, GraphQL, and Relay, the remainder focused on areas of tech that I rarely if ever consider. Talks covered subjects like virtual reality, hardware, and graphics. I may never focus the majority of my time on any of these, but it’s eye-opening and motivating to see people pushing the limits of what can be done.
Isaac Salier-Hellendag announced Draft.js, a new open-source framework for building rich text editors. I’ve worked on exactly this problem, implementing a textarea that allows for Facebook-style (using @) mentions, so I totally resonated with his walkthrough of the problem and implementation, and I’m excited to give Draft.js a try.
Jared Forsyth addressed exactly the situation I’m in, providing an overview of React, Redux, and Relay (with discussions of ClojureScript and Om/next mixed in) and how to determine which to use and when.
Nicolas Gallagher, who’s SUIT CSS project I’ve used, pushed things a step farther and proposed taking styles a step farther (moving CSS entirely into JS) in his talk on React Native for Web.
Jamison Dance stepped away from React long enough to discuss Elm and what JavaScript can learn from it (read: immutability, types, pure functions). Fantastic talk with great examples and fun slides.
Any post-conference list would be incomplete without mentioning the things I’m excited to explore and implement:
As I already mentioned, I want to give Draft.js a long look and consider using it in production.
I was already interested in GraphQL and Relay, and want to take a few days to see if it could make sense at work.
I’m all for moving away from CSS in favor of JavaScript solutions, so I want to learn from React Native for Web and consider the OSS solutions for JS styles.
My app at work, like so many others, is slow on app initialization, so I want to consider how to improve that based on ideas presented at the conference.
I want to finally give React Native a try in a side project.
Finally, I’m already sold on ideas from functional programming like immutability and reducing side effects, but I want to check out Flow for gradual type checking and I want to learn Elm rather than only doing FP in JavaScript.
]]><![CDATA[The Hammer of JavaScript (and Other Tools for Other Nails)]]>2016-02-08T16:10:04+00:00http://cek.io/blog/2016/02/08/javascript-hammerThe one where I get a harsh reminder to question my instincts from a real-life experience of this XKCD comic.
As a mental exercise, a friend proposed the following potential interview question: given a directory with 10,000 files of text, how would you extract all the phone numbers from that directory into a single file?
My immediate thought: this would be a basic assessment of someone’s knowledge of:
regular expressions to match patterns of numbers
how to programmatically read/write files
basic algorithmic complexity for iterating through files quickly.
I even knew how I’d implement it: use node’s filesystem module to read the files, parse them for regex matches, and write all matches to a new file.
I was intrigued enough that I decided to prove it out. I wrote a basic phone number regex by hand (\d{3}(-|\s|\.)?\d{3}(-|\s|\.)?\d{4}\ (for 3 digits, 3 digits, and 4 digits separated by hyphens, periods, spaces, or nothing), and looked into popular phone number regexes. I realized how unfamiliar I am with Node’s filesystem module (readdir and readFile and writeFile). Then I got curious about publishing npm packages. Before I knew it, I’d spent a couple hours and produced a somewhat polished npm project for this hypothetical task.
And it was all wrong.
The thought process I used was logical. My work as a software engineer focuses almost entirely on the web, JavaScript, build tools, UI features, HTTP servers. I’m comfortable with databases, front- and back-end code, version control, and countless other things. But that’s a small subset of software! Classic hammer/nail.
To Wikipedia:
Software: any set of instructions that directs a computer to perform specific tasks or operations.
Software is about problem-solving. But problems can’t be solved well without being understood. And they won’t be well understood if we assume we should use the same solution every time. There’s something to be said for using the tools you know, but software also requires a humility to recognize when a given tool is the wrong one.
In this case, I skipped the step of analyzing the problem. I didn’t think about the specifics of the problem, the tradeoffs of time, or the alternative solutions I could choose. This was a one-time, approximate task. It was unlikely to be repeated often enough to make automating worthwhile. And yet I instinctually went with what I knew, implementing a “good”, “complete” solution that was really just a picture of overengineering.
For a problem like this, why use another language or abstraction when it can be done via the command line, the text interface for the computer itself and a much more direct interface with the filesystem? Why use a language like JavaScript that’s best suited for the web or pull in Node just for the sake of using a tool I know?
These are questions I won’t soon forget to ask myself when I take on a new problem. Hopefully that’ll prevent me from falling into traps that webcomics are made of. I know for sure that, next time I’m presented with a problem of finding text within a filesystem, I’ll remember that tools like grep were made for exactly that. A simpler, less time-instensive, and more appropriate solution.
]]><![CDATA[JavaScript's Call Stack, Callback Queue, and Event Loop]]>2015-12-03T14:01:39+00:00http://cek.io/blog/2015/12/03/event-loopIn this video, Philip Roberts clears up a lot of the details surrounding JavaScript’s call stack, callback queue, and event loop. Feel free to skip this blog post and spend a half hour watching the video instead. But if you’d rather skim my highlights, don’t let me stop you!
What is JavaScript
What is JavaScript anyway? Some words:
It’s a single-threaded, non-blocking, asynchronous, concurrent language”
It has a call stack, an event loop, a callback queue, some other apis and stuff
If you’re like me (or Philip Roberts, it seems), these words themselves don’t mean a ton. So let’s parse that out.
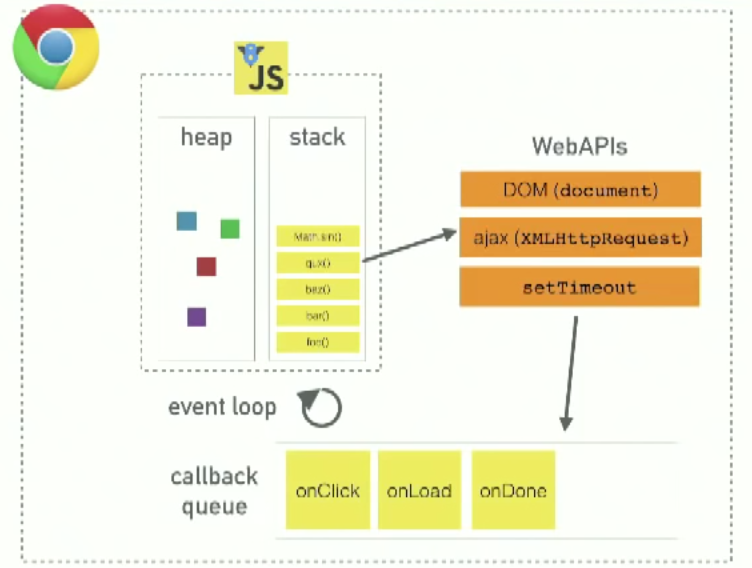
JavaScript Runtimes
JavaScript runtimes (like V8) have a heap (memory allocation) and stack (execution contexts). But they don’t have setTimeout, the DOM, etc. Those are web APIs in the browser.
JavaScript as we know it
JavaScript in the browser has:
a runtime like V8 (heap/stack)
Web APIs that the browser provides, like the DOM, ajax, and setTimeout
a callback queue for events with callbacks like onClick, onLoad, onDone
an event loop
What’s the call stack?
JavaScript is single-threaded, meaning it has a single call stack, meaning it can do one thing at a time. The call stack is basically a data structure which records where in the program we are. If we step into a function, we push something onto the stack. If we return from a function, we pop off the top of the stack.
When our program throws an error, we see the call stack in the console. We see the state of the stack (which functions have been called) when that error happened.
Blocking
An important question that this relates to: what happens when things are slow? In other words, blocking. Blocking doesn’t have a strict definition; really it’s just things that are slow. console.log isn’t slow, but while loops from 1 to 1,000,000,000, image processing, or network requests are slow. Those things that are slow and on the stack are blocking.
Since JS is single-threaded, we make a network request and have to wait until it’s done. This is a problem in the browser—while we wait on a request, the browser is blocked (can’t click things, submit forms, etc.). The solution is asynchronous callbacks.
Concurrency, where we realize there’s a lie above
It’s a lie that JavaScript can only do one thing at a time. It’s true: JavaScript the runtime can only do one thing at a time. It can’t make an ajax request while doing other code. It can’t do a setTimeout while doing other code. But we can do things concurrently, because the browser is more than the runtime (remember the grainy image above).
The stack can put things into web APIs, which (when done) push callbacks onto task queue, and then…the event loop. Finally we get to the event loop. It’s the simplest little piece in this equation, and it has one very simple job. Look at the stack and look at the task queue; if the stack is empty, it takes the first thing off of the queue and pushes it onto the stack (back in JS land, back inside V8).
Louping it all together
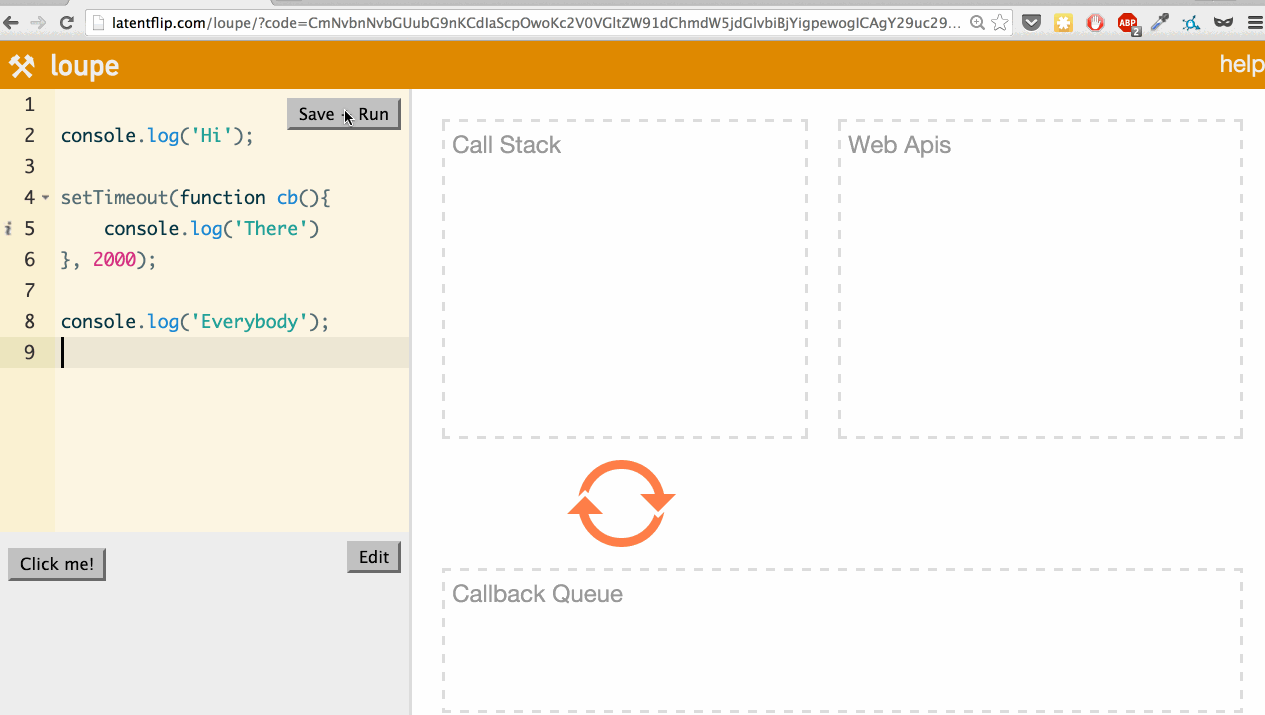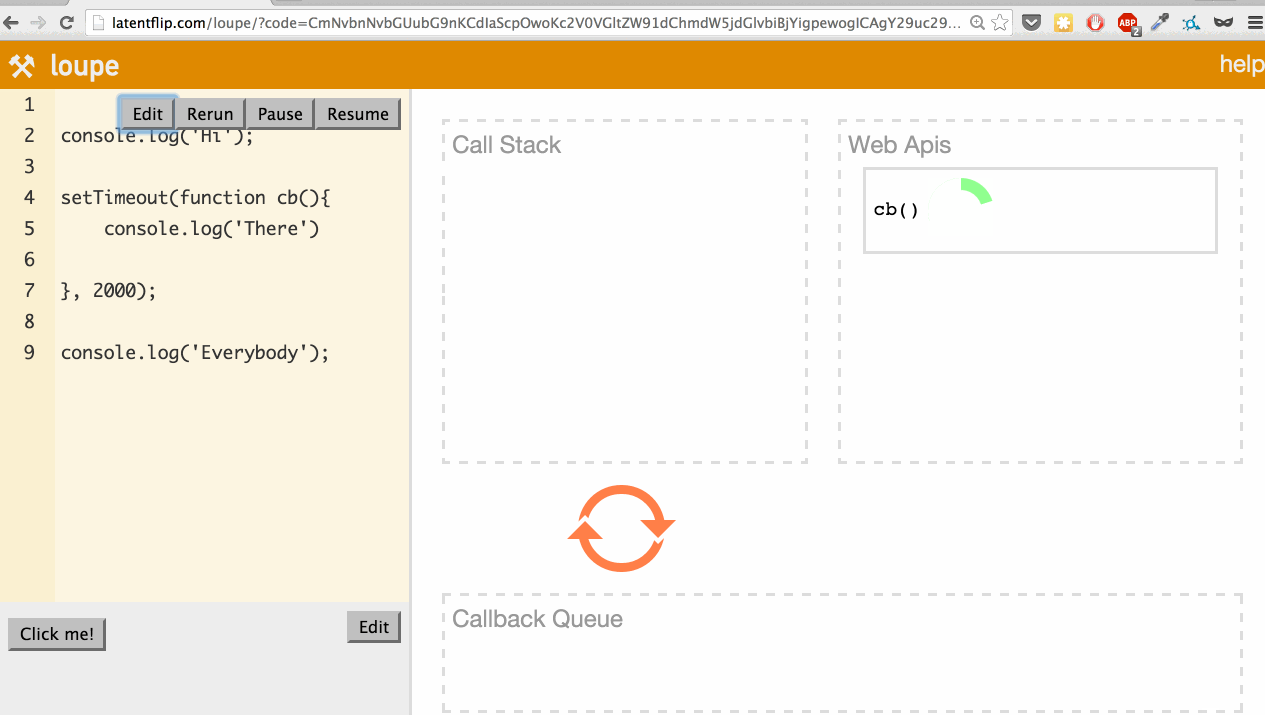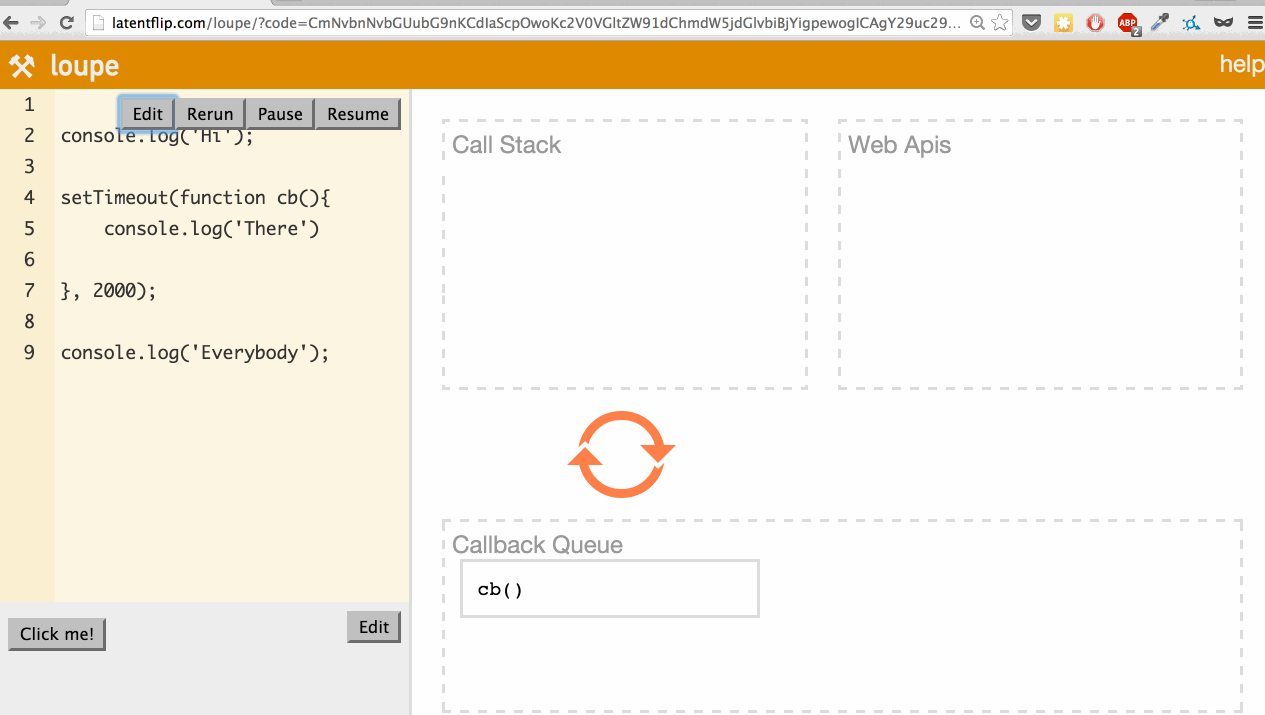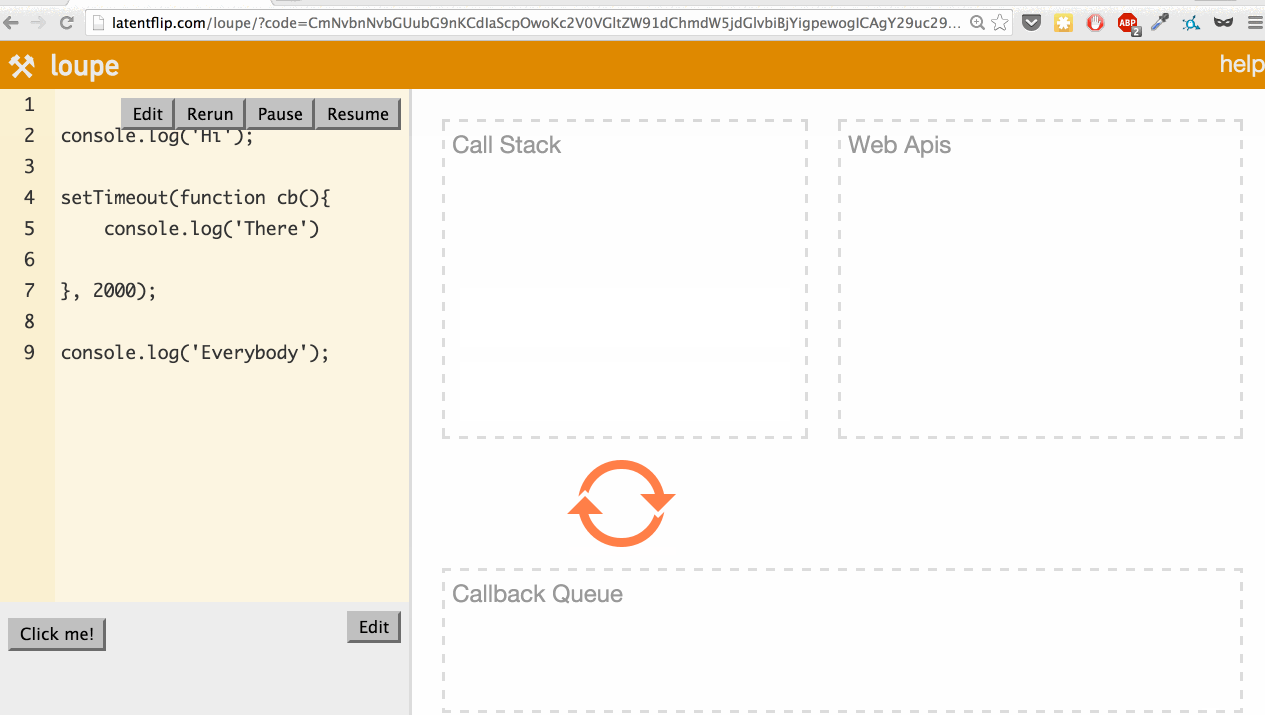
Philip built an awesome tool to visualize all of this, called Loupe. It’s a tool that can visualize the JavaScript runtime at runtime.
Let’s use it to look at a simple example: logging a few things to the console, with one console.log happening asynchronously in a setTimeout.
What’s actually happening here? Let’s go through it:
We step into the console.log('Hi'); function, so it’s pushed onto the call stack.
console.log('Hi'); returns, so it’s popped off the top of the stack.
We step into the setTimeout function, so it’s pushed onto the call stack.
setTimeout is part of the web API, so the web API handles that and times out the 2 seconds.
We continue our script, stepping into the console.log('Everybody') function, pushing it onto the stack.
console.log('Everybody') returns, so it’s popped off the stack.
The 2-second timeout completes, so the callback moves to the callback queue.
The event loop checks if the call stack is empty. If it were not empty, it would wait. Because it is empty, the callback is pushed onto the call stack.
console.log('Everybody') returns, so it’s popped off the call stack.
An interesting aside: setTimeout(function(...), 0). setTimeout with 0 isn’t necessarily intuitive, except when considered in the context of call stack and event loop. It basically defers something until the stack is clear.
Considering UI render performance
To this back to something more surface level, something we deal with every day, let’s consider rendering. The browser is constrained by what we’re doing in JavaScript. It would like to repaint the screen every 16.6ms (or 60 frames/second). But it can’t actually do a render if there’s code on the stack.
As Philip says,
When people say “don’t block the event loop”, this is exactly what they’re talking about. Don’t put slow code on the stack because, when you do that, the browser can’t do what it needs to do, like create a nice fluid UI.
So, for example, scroll handlers trigger a lot and can cause a lagging UI. Incidentally, this is the clearest explanation I’ve heard of debouncing, which is exactly what you need to do to prevent blocking the event loop (that is, let’s only do those slow events every X times the scroll handler triggers).
Closing
In summary, that’s what the heck the event loop is. Philip’s talk helped me understand a lot of what JavaScript is, what it isn’t, which parts of it are runtime vs. browser, and how to use it effectively. Give the talk a watch!
]]><![CDATA[Pruning Code]]>2015-11-21T17:23:14+00:00http://cek.io/blog/2015/11/21/code-pruningIt was Friday afternoon, the end of the day, at the end of a long week of urgent bugfixes to prepare a release. Our next features hadn’t been fully designed and approved, all the high-priority bugs had been identified and fixed, and I was left with a few hours to choose what to work on.
These moments are some of my favorites, opportunities to focus on the important/non-urgent tasks like performance improvements, refactors, new technologies, and code cleanup. So I spent the last few hours of the day on that last item: pruning old code from the codebase.
We all know that pruning is about removing the superfluous, which is by definition a good thing (“superfluous” being “unnecessary”, after all), but the benefits of pruning also include:
Ok, ok, we’re not talking about plant health, risk of falling branches, or yield of flowers and fruits. But it’s a pretty straightforward metaphor for code.
The pull request I ended up submitting did three things (removed, removed, removed, like pruning):
It removed the /** @jsx React.DOM */ pragma, which has been unnecessary since React 0.12 (we’re currently running 0.13).
It removed Immutable as a global variable (we’re using Immutable JS on most—but not all—pages, and we want to explicitly require libraries for each file/component, plus…yeah).
It removed a couple helper functions from a utility file the depends on lodash.js, which largely overlaps with our Ramda.js library.
These are simple things. Remove unnecessary lines of code. Clarify what a given file is doing by making modules more explicit. Reduce the number of dependencies and the weight of the codebase.
These are clearly beneficial things. Deleting the unnecessary reduces mental overhead. Explicit requires ease our ability to reason about a piece of code. Removing an external library improves performance.
Simple, beneficial, and yet when do these things get accomplished? As I referenced above, rarely. It was only after feature development, testing, and bugfixing that I even considered it. To some degree that’s on me: it’s a technical discipline like performance or code quality that needs to be considered at each step along the way. But it’s also on the development process and management: if it’s not prioritized and time isn’t allotted, it won’t happen! That simple.
Anyway, that’s my argument for code pruning. Regardless of whether anyone else finds it valid, it’s a personal goal of mine to spend a couple hours a week on exactly that. Removing dependencies, deleting dead code, refactoring. And who knows, perhaps with a little more disciplined code pruning along the way, code quality will improve and our team will have fewer weeks of urgent bugfixes.
]]><![CDATA[An Imperative Declaration]]>2015-10-23T21:42:28+01:00http://cek.io/blog/2015/10/23/imperative-declarationA few hours ago, my understanding of imperative and declarative programming was effectively: imperative is about “how” something should happen and declarative is about “what” should happen. Not exactly authoritative, so I spent these last couple hours trying to clear that up by finding conclusive answers to the following questions:
What’s the difference between imperative programming and declarative programming?
Is functional programming a subset of declarative programming?
If so, what’s an example of declarative programming that’s not functional?
Unfortunately, no definitive answers. Or perhaps too many “definitive” answers. So here’s where I stand.
The Backstory
Let me back up for a second. I went through a similar exercise a little while back. Google even pointed me to this handy article, which I found so useful that I summarized it in a StackOverflow answer.
I was pleasantly surprised by the three upvotes that came over the next few months, but of course all pleasant things must come to an end:
As with frighteningly many answers to this question, your example of ‘declarative’ programming is an example of functional programming. The semantics of ‘map’ are ‘apply this function to the elements of the array in order’. You’re not allowing the runtime any leeway in the order of execution.
Silly me, thinking I’d grasped a complex but fundamental concept, and sillier me, thinking I should share it. On the internet.
Thus began my quest to answer those three questions. (1) What is the difference between imperative and declarative? (2) Can I safely call functional programming a subset of declarative programming? (3) If so, what’s an example of declarative programming that isn’t functional?
Defining the Question(s)
I first tried to make sense of the critique I’d received on StackOverflow: “…your example of ‘declarative’ programming is an example of functional programming.” I suppose that’s what rendered my answer inappropriate for the question “What is the difference between declarative and imperative programming?”. Easy solution—just look back to the accepted answer…and find that the same commenter left a very similar critique.
This seemed to imply that functional programming and declarative programming are not synonymous (which I already believed), but also that there’s a significant difference between declarative programming and functional programming (which I hadn’t recognized). So what is it? Going back even farther, if this is a valid critique, what’s the difference between imperative and declarative to begin with? I decided to reassess my answer.
Definitions
Imperative Programming:
“Telling the ‘machine’ how to do something, and as a result what you want to happen will happen.” (Latentflip)
“A programming paradigm that uses statements that change a program’s state. In much the same way that the imperative mood in natural languages expresses commands, an imperative program consists of commands for the computer to perform. Imperative programming focuses on describing how a program operates.” (Wikipedia)
“Any programming language that specifies explicit manipulation of the state of the computer system.” (Foldoc)
Declarative Programming:
“Telling the ‘machine’ what you would like to happen, and let the computer figure out how to do it.” (Latentflip)
“A programming paradigm…that expresses the logic of a computation without describing its control flow. Many languages applying this style attempt to minimize or eliminate side effects by describing what the program should accomplish in terms of the problem domain, rather than describing how to go about accomplishing it as a sequence of the programming language primitives (the how being left up to the language’s implementation).” (Wikipedia)
“Any relational language or functional language. These kinds of programming language describe relationships between variables in terms of functions or inference rules, and the language executor (interpreter or compiler) applies some fixed algorithm to these relations to produce a result.” (Foldoc)
Takeaways:
How (imperative) vs. what (declarative)
Using control flow and mutating state (imperative) vs. minimizing/eliminating control flow and side effects
Here’s where we already see some divergence in definition. Minimizing vs eliminating opens us up to an ambiguity. Does declarative programming necessitate absolutely no side effects, or just a preference for immutability? Is imperative programming about the lowest level of specified instructions, or just less abstraction?
Arriving Back Full Circle
With these thoughts in mind, I’d argue that declarative and imperative are relative terms, not absolute black and white, but a spectrum of lighter and darker gray. Generalizing, declarative programming is about specifying the “what”, by way of certain abstractions (for example, functional operations like map) or by removing abstractions (for example, plain HTML rather than jQuery DOM manipulation), whereas declarative programming is about the “how”, using lower level steps (for example, for loops).
So I stand by my original sentiments, and my original answer on StackOverflow. If we think of imperative and declarative as a spectrum rather than a binary either-or, we can use it as an effective part of our vocabulary rather than a confusing semantic argument.
That’s where I’m at anyway. I hope you don’t find it “frighteningly” off-target.
]]><![CDATA[Performance Process: Takeaways From AEA]]>2015-10-09T18:39:03+01:00http://cek.io/blog/2015/10/09/performanceThe stars have aligned lately to focus my attention on performance. Consider the following:
A few months ago, I was tasked with assessing and documenting the differences between our app’s functionality/performance in Chrome vs. Firefox.
This exercise resulted in a pull request that improved Firefox performance by over 2 seconds (~25%) on initial page load.
What does this add up to? I’ve been thinking a lot about performance, particularly front end performance of web apps. In this post, I’ll summarize some takeaways from AEA regarding performance, particularly as they relate to integrating performance into planning and design.
Set up for failure
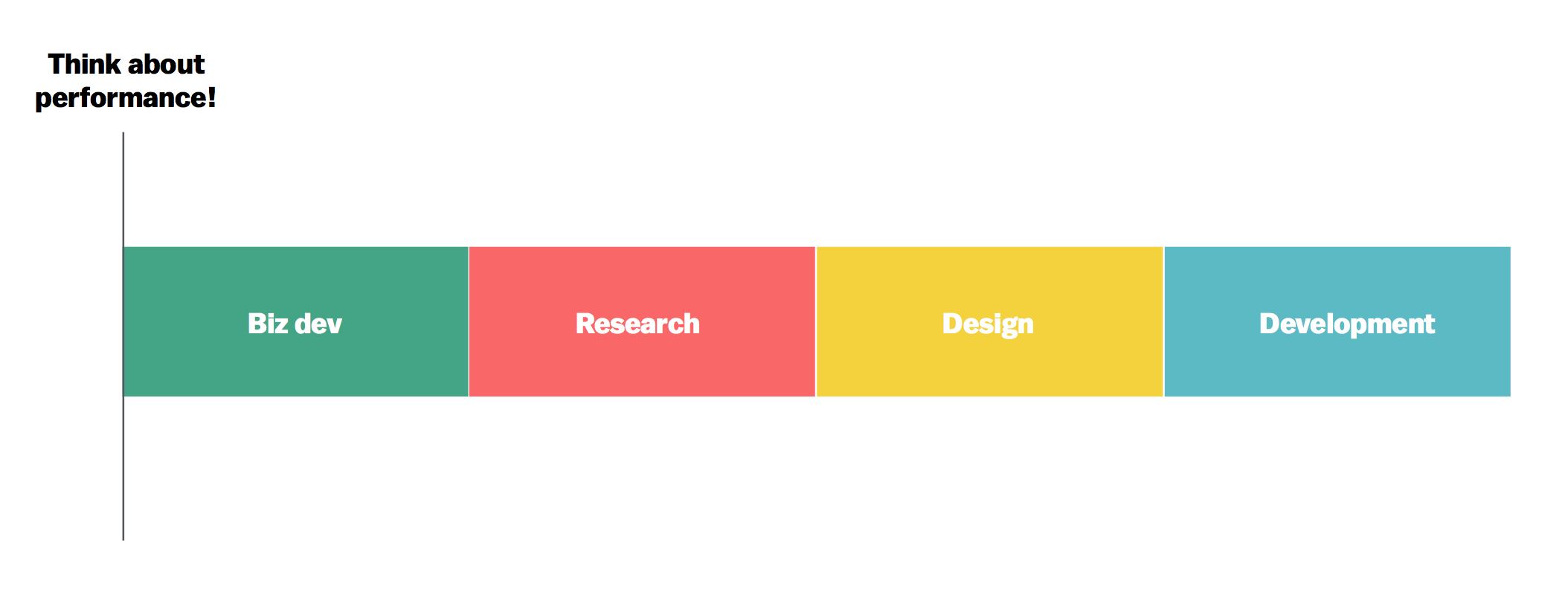
Summarizing a few points from Yesenia’s talk, consider this project plan, one that we’ve all presumed to follow:
But then realize that, due to biz dev requirements, delays in research, and longer-than-expected design time, all while keeping the same sprint/client/deployment deadline, the actual project plan looks like this:
We’ve all seen it! And it probably happens more often this way than the ideal case. What’s the definition of insanity again?
Now I could speculate and hypothesize about the underlying issues of failed project management, but I’ll leave that to someone else. I want to focus on performance. A question: with that development timeline in mind, when do we think about performance? During the software development segment, right?
But why? We developers think we can implement user functionality, meet the design specs, and still have time left over to optimize at the end. But that never happens. Could we not consider performance at the beginning of the process?
We need to think about performance as a design feature. We need to think about performance early. We need to prioritize page speed and load times just as much as UX and beautiful interfaces. But how?
Performance Budgets
“We only have the budget for a poor job”
I’m not sure we’re being cheap or smart by thinking about performance this way. We don’t have any budget at all! A theme throughout AEA, and not just in Yesenia’s and Lara’s talks, was setting a performance budget.
Yesenia explained that a performance budget is both “a performance goal used to guide design & development” and “a tangible way to talk about performance.” How well do those conversations about performance-intensive features usually go? For developers, it’s often either “no, we can’t do that” or a resigned “ok, I guess we have to do it.”
One incredible trick will render 728,000 Google results obselete!
What if, instead of a win-lose scenario between designers and devs, the conversation was framed around a budget? We talk about the inherent tradeoffs between technologies, so why not consider performance tradeoffs in discussions about design?
“But how do I go about setting a performance budget?”, you might ask. Yesenia and Lara made some suggestions:
Browser-based approach: “our pages should weigh no more than 400kb, and make no more than 15 requests.”
User experience-based: “our pages should take no more than 10 seconds to load over a sub-3G connection.”
Look to your competitors: aim for a 20% improvement over your competitors.
I’m still working on this, on how to practically establish a performance budget on the job. I don’t have access to my competitors’ product, so for now I can only set the goal as arbitrarily better performance.
One thing I will say: everything I’ve said in this blogpost has to be a culture change. Stealing from Lara’s talk, it can’t be all on one individual. You have to establish a culture of performance.
"There should be no performance cops or janitors. It's not sustainable. You need a culture of performance." @lara_hogan#aeaaus
]]><![CDATA[An Event Apart]]>2015-10-08T22:09:32+01:00http://cek.io/blog/2015/10/08/an-event-apartThis week, I had the good fortune of attending An Event Apart in Austin, TX. Coordinated by the same great people behind A List Apart, An Event Apart (AEA) is two days of fantastic talks about the web—content, design, development—and a full-day workshop (A Day Apart). Many of the concepts we now take for granted as web best practices, like mobile first and responsive design, have been introduced and elaborated at AEA events.
Before I continue, some thanks are in order. AEA made three scholarships available to Flatiron School alumni. Now, in retrospect, I realize the value of attending is well worth the $1,000+ price tag, but the reality is: I wouldn’t have been able to justify that cost on my own. So some major thank yous for making this happen, first to AEA for offering those scholarships, and then to Flatiron School for enabling that hookup. Thank you!
Moving on, I want to share some of my notes and highlights from the three days. For a quick summary of the conference in the form of 140-character highlights, #aeaaus is a great place to start. A summary of my takeaways from the conference (as well as my full notes) are below.
My full unfiltered/unedited notes can be viewed here, and videos of all talks will be posted online at some point, so you should sign up here. For now, these are my highlights/summaries of each talk, some of which may turn into full posts.
Jeffrey Zeldman opened the conference by telling his personal narrative, from starving artist to professional creative to disillusioned advertiser to web practitioner. Takeaways: Talk about the problems you’re solving, not the aesthetics; attitude trumps work; blog!
Yesenia Perez-Cruz discussed design from the perspective of performance. Takeaways: performance isn’t a last-minute add-on, it’s part of the UX; consider performance at the beginning.
Jen Simmons presented modern layouts and recent/upcoming additions to CSS. Takeaways: we see the same layout with sidebar everywhere; use CSS shapes/flexbox; layout should serve content.
Cameron Moll walked us through interfaces and the ways we interact with them. Takeaways: the best interface is the one within reach; forget about mobile/desktop and instead build a unified interface.
Karen McGrane summarized issues around content and how it should be separated from form. Takeaways: separating form from content makes web design much easier than an interconnected blob of a website.
Ethan Marcotte argued that laziness is good, that less is more when it comes to responsive design. Takeaways: use flexible layout systems rather than device-specific designs.
Lara Callender Hogan built on Yesenia’s talk about performance Takeaways: we optimize for design/layout but not page speed; need happy medium of aesthetics and speed; tips for image optimization; need a culture of performance; set a performance budget.
Eric Meyer presented an incredibly vulnerable talk about personal tragedy and how his experience as someone in crisis informs his understanding of web design Takeaways: design with crisis-driven personas in mind; empathy; don’t consider just the ideal user.
Jason Grigsby got into the nitty gritty of responsive images. Takeaways: responsive images matter for resolution switching and art direction; look-ahead preparser.
Brad Frost framed web design from the perspective of atoms –> molecules –> organisms. Takeaways: design systems of components not pages.
Matt Haughey brought a customer service perspective to web design. Takeaways: everyone at Slack does customer service; need to have empathy for the user.
Jeremy Keith took us through the history of the web and argued for using basic, supported technologies that don’t break. Takeaways: identify core functionality and implement using simplest technology, then enhance.
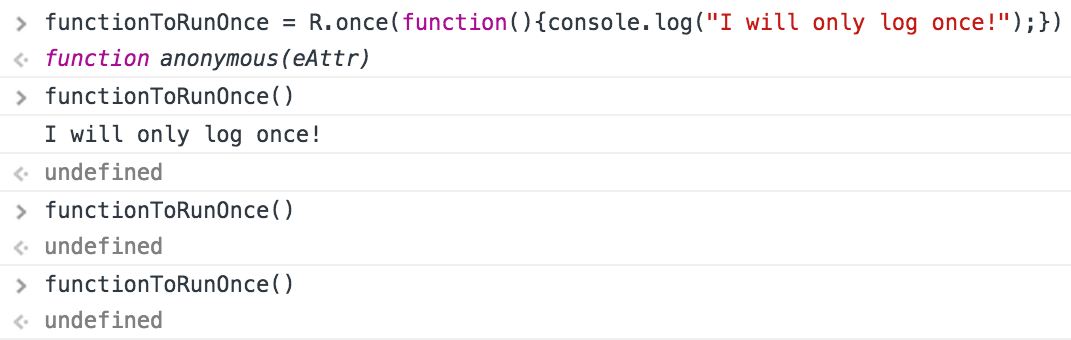
]]><![CDATA[Ramda's Once]]>2015-07-14T16:29:18+01:00http://cek.io/blog/2015/07/14/onceSomeone recently described to me that, in an interview, he was asked to implement a function that would only run once, even if invoked multiple times. This immediately made me think of Ramda—my go-to JavaScript library (think Underscore or lodash, but with a little more functional programming flavor)—and its once function:
Great, once “accepts a function fn and returns a function that guards invocation of fn such that fn can only ever be called once, no matter how many times the returned function is invoked.” Getting back to the original question (i.e., in an interview), this would be one kind of answer. It would show knowledge of the JavaScript ecosystem, some of its libraries (and why to use them), and how to apply it to a specific problem.
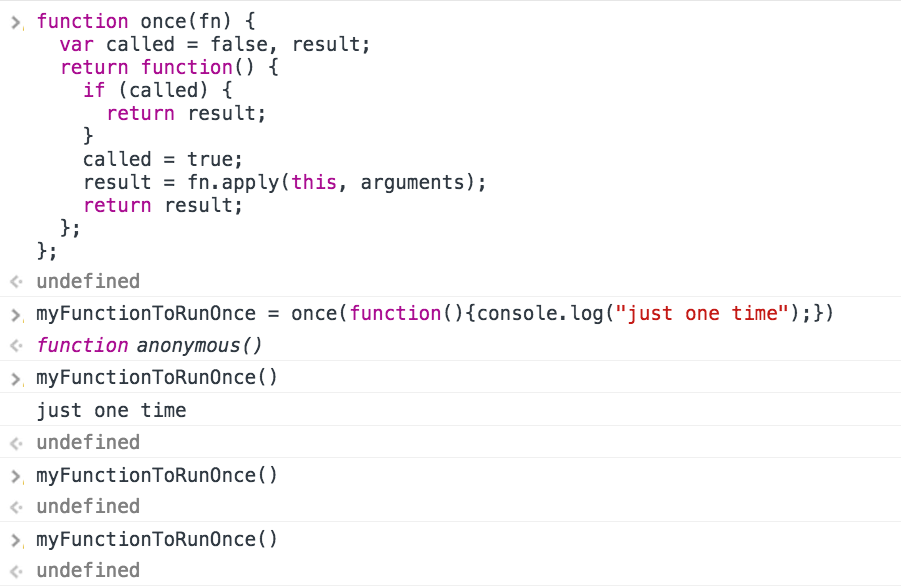
That said, let’s go deeper—how would we implement once from scratch? Since Ramda’s implementation worked so well for us, let’s look no further than Ramda. Looking at the source, it’s relatively straightforward to see what’s going on:
Let’s ignore _curry1 for now (though we’ll get to it), and rewrite as follows:
And there we have it! So what’s actually happening here? The first several lines are simple: we declare the variables called (initialized to false) and result, return result if called is true, otherwise set called to true and then assign result = fn.apply(this, arguments);.
What is that line doing? It’s using apply(), which “calls a function with a given this value and arguments provided as an array”. It’s a way of dealing with scope, making sure we pass the right value of this to fn. In our example above (console.log...), this isn’t an issue, so we could plausibly replace the line in question with result = fn(arguments);.
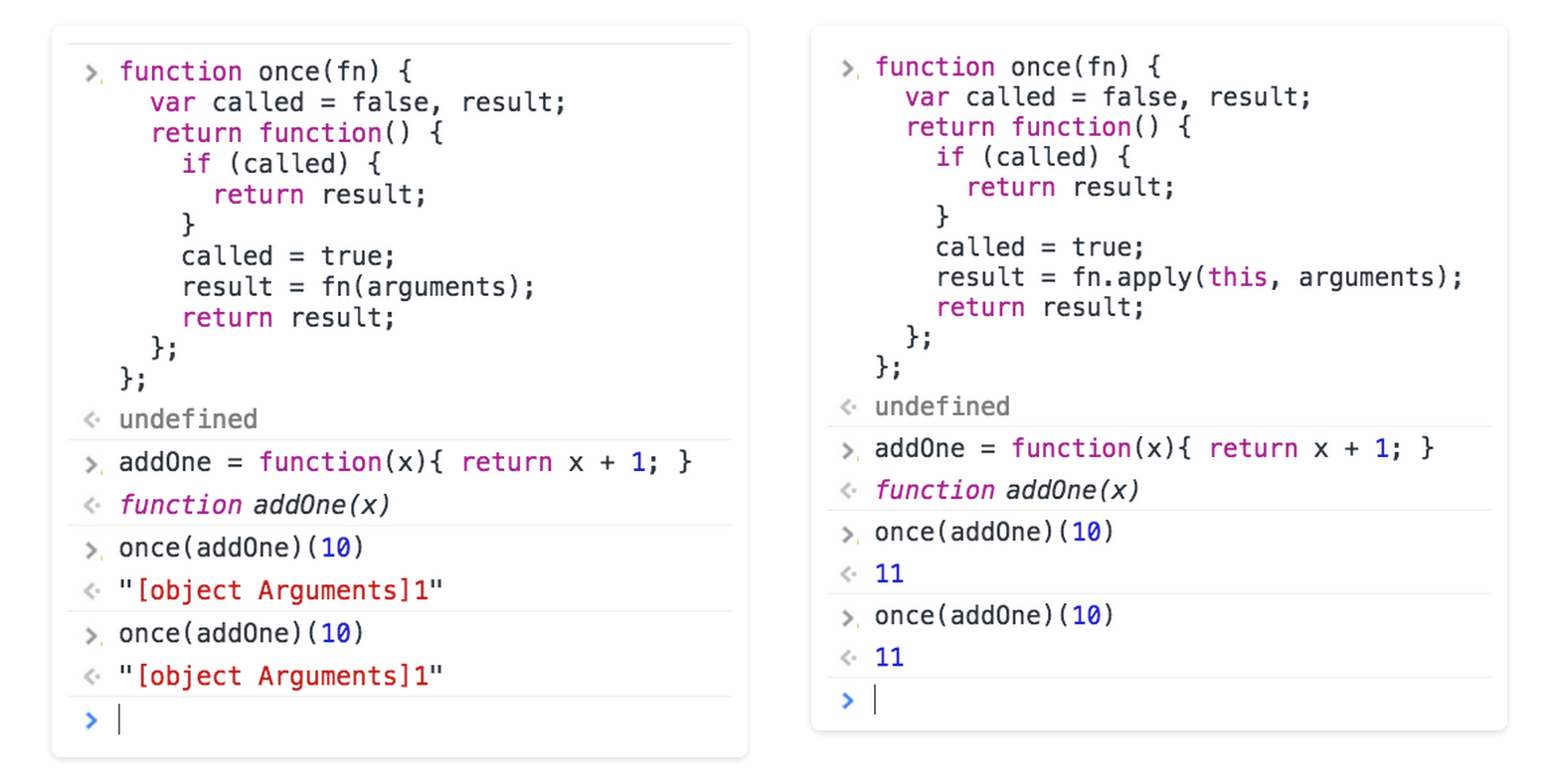
It is an issue, however, when scope and this matter. For example, using Ramda’s example of wrapping an addOne function (var addOneOnce = R.once(function(x){ return x + 1; });) using once, we can see that not using apply() (left) breaks the adding behavior, but it works when using apply() (right).
This occurs (on the left) because without passing the correct value for this, x in the addOne function becomes "[object Arguments]", which, when 1 is added, becomes "[object Arguments]1". On the other hand (on the right), given the correct value for this, x becomes 10 (or whatever argument we pass) and the result is correct.
And that about concludes this post, with one open question remaining: currying? Ramda’s implementation of once uses curry1, in keeping with its API (functions first, data last) and functional style. Currying is just a way of turning a function that expects n parameters into one that, when supplied less than n parameters, returns a new function awaiting the remaining parameters. It’s a handy way that Ramda enables us to build functions, pass those functions around as first-class objects, and call when ready. Back to our once examples, currying is what’s happening when we call once(addOne) and see function anonymous(). once(addOne) expects one more parameter, so we call once(addOne)(10) and get 11.
]]><![CDATA[Rethinking UI Patterns: D3 and React]]>2015-06-23T13:17:36+01:00http://cek.io/blog/2015/06/23/react-d3Author’s note: I’ve followed up on this post with another one. I’m no longer a fan of building up SVG elements in React components the way I propose in this post. You should read the other post to see what I recommend.
Imagine the entirety of your organization’s chatroom communications. Imagine making sense of those communications in a single interactive visualization, one that factors in date and time, chatroom name, individual participants’ names, and message content.
I recently implemented just such a feature. While something like this of course requires back end analytics, aggregations of data, and “data science” that can handle such “big data,” it also relates to user interface (UI), the subject of this blog post.
UI background
Until recently, this app’s client-side UI was built entirely in Ember.js, a framework intended for “ambitious” applications (and thus a good fit!). Over time, however, the UI team came to realize some of Ember’s limitations, some of those conventions and patterns inherent to the framework that—rather than making developers’ lives easier, as is any framework’s aim—posed challenges to the organization and maintenance of our codebase.
Enter React.js, a UI library that solely addresses issues in the view layer. Over the last 5-6 months, we have been porting Ember code over to React, started using React for all greenfield components, and made React the standard for our UI. This blog post won’t cover the litany of (fiercely debated) pros and cons of Ember vs. React, but suffice it to say that React has made us on the product development team unanimously happier.
D3
All of that is just background to the feature I initially described, because a data visualization isn’t implemented solely in Ember or React. Or is it?
The old way
The short answer is no. To effectively create data visualizations, we have leveraged D3.js, a JavaScript library for manipulating documents. D3 functions similarly to jQuery in that it emphasizes selectors and listeners; for example, to initialize a D3 svg, we might write d3.select('body').append('svg') #... and, from there, append rectangles and lines, bind click and hover actions, etc. Not so different from a basic jQuery application ($('button').on('click', function()...)).
That said, what D3 ultimately produces is a series of DOM elements, specifically SVG elements. Some basic D3 code might look like:
There are multiple ways to wire D3 up to a given web framework, but it’s ultimately a script that runs to build the component in the DOM. Our old pattern was loosely the following:
fetch model in the route
set up component properties in the controller
render the component in the template:
in Ember’s didInsertElement hook in the component, run the D3 script that selects body and appends SVG
Made new
Until recently, we had been able to maintain and reuse our Ember D3 components, but this chat timelines visualization required a brand new D3 component, one we decided to write in React.
My initial instinct, as with simpler React components, was to render the component with properties and run the D3 script in React’s render or componentDidMount hook. What became clear, however, was that we didn’t need to run the D3 script at all. In place of d3.select(...).append(...) we could simply build up svg elements in the render hook.
This approach, while going against my initial instinct of using D3’s pattern, aligns well with React’s strengths of one-way data flow and components that are easier to reason about than traditional data binding. It’s a declarative approach that expresses what it does, as opposed to an imperative approach that expresses how it’s done. And it has benefits of composibility and extensibility—rather than selecting and appending as additional design specs come in, we can componentize everything—bars, axes, labels, plots—to reuse later or modify with greater control.
And that earlier question about data visualizations being written entirely in a framework? Considered this way, we can construct the SVG elements directly in React, something like this:
You can pretty quickly see how the inner rectangles could be pulled out as components of their own, as could axes, labels, etc. We’ve found this pattern to be much easier to reason about when building visualizations in our UI. So here’s to rethinking UI patterns and, as a result, writing code that’s easier to reason through.
]]><![CDATA[Scratching My Own Itch: A Chrome Extension Story]]>2015-03-24T21:10:39+00:00http://cek.io/blog/2015/03/24/chrome-extensionWhen we submit pull requests on BitBucket, my coworkers and I will generally draw attention when they are net-negative, removing more lines of code than they add. In some cases, it’s pretty obvious—entire files being deleted, etc. Oftentimes, however, it requires doing a bit of mental math to tally the difference between lines added and lines removed. For that reason, it’s gratifying to “scratch my own itch” by installing this extension to do it for me.
The “problem” already had a solution of sorts, in the form of a short jQuery script a coworker had pulled together:
A simple solution that, when run in the browser console, would log the offset. I just wanted to make it even simpler by removing that one extra step. That meant setting up a Chrome extension, which was a far easier process than I thought it might be.
A brief how-to
Set up a new directory with a manifest.json file, with a name, manifest_version of 2, a version,
To see it working, add an icon.png and list that file in manifest.json under browser_action.default_icon. By now, manifest.json should look something like this:
{
"name": "Hello World!",
"manifest_version": 2,
"version": "1.0",
"description": "My first Chrome extension.",
"browser_action": {
"default_icon": "icon.png"
}
}
Go to chrome://extensions, tick ‘developer mode’, click ‘load unpacked extension’, and select your new folder–note your icon appear in the top right of your browser, next to your other extensions.
At this point, you have a Chrome extension! Of course, now you need to decide what you want it to do, but getting it started is that trivial. In my case, I didn’t even keep the default icon, since I just want a script to run on certain domains.
Publishing the extension requires a Chrome developer account (which requires a $5 payment), which you can set up here. From there, publishing the extension just requires compressing the folder to a zip file (right-click the folder, compress) and uploading.
]]><![CDATA[Old and New Years]]>2015-01-03T17:14:20+00:00http://cek.io/blog/2015/01/03/new-yearHappy new year! A resolution of mine for 2015 is to write more—not just code, which is itself an admirable goal, but human-readable English. This was motivated by (1) the advice in this article I read recently, which is not new advice, (2) the hope that, for all the benefits of specialization, there’s value in maintaining competence in both programming and verbal language, and (3) the fact that I like writing! So you can expect more consistent posts than the last six months have yielded.
My commitment to blog is also part of a larger goal: to further establish myself as a software engineer, which means (among other things like improving my technical skills) better understanding the industry. Recognizing my ignorance about computer science and its history, I put Walter Isaacson’s “The Innovators” on my Christmas wishlist.
I’m only two chapters in, but I’m already struck by two major things: (1) the main thesis arguing that innovation is more attributable to collaboration than to singular genius and (2) the convergence of technological advances in the year 1937, all of which accelerated towards the modern computer.
Isaacson writes:
New approaches, technologies, and theories began to emerge in 1937… It would become an annus mirabiliis of the computer age, and the result would be the triumph of four properties, somewhat interrelated, that would define modern computing.
He defines those four computing properties as digital, binary, electronic, and general purpose, and he summarizes the following key individuals and their contributions in (and around) 1937:
Person(s)
Contribution
Alan Turing (Cambridge/Princeton)
Published paper of mathematical theory (addressing Hilbert’s Entscheidungsproblem), with the byproduct of the conceptual “Logical Computing Machine”, which became known as the Turing Machine (“It is possible to invent a single machine which can be used to compute any computable sequence”).
Claude Shannon and George Stibitz (Bell Labs)
Shannon figured out that electrical circuits could execute Boolean logical operations using an arrangement of on-off switches. Stibitz built the Complex Number Calculator which, based on Shannon’s insight, showed the potential of circuit relays to do binary math, process information, and handle logical procedures.
Howard Aiken (Harvard)
Began plans on the Mark I which, when completed in 1944 under IBM and the Navy, was fully automatic—it could run for days without human intervention—as well as digital (though non-binary and partially mechanical).
Konrad Zuse (Berlin)
Finished a calculator prototype, the Z1, that was binary and could read instructions from a punched tape (though mechanical). This ultimately gave way to the Z3, which was the first fully working all-purpose, programmable digital computer.
John Vincent Atanasoff (Ames, Iowa)
Conceived the first partly electronic digital computer, which solved linear equations. It used mechanically rotating cylinders to replenish electrical charges in condensers and thus maintain memory. Atanasoff was also (disputedly) the inspiration for John Mauchly’s work.
John Mauchly and J. Presper Eckert (UPenn, 1940s)
With funding from the US War Department, built ENIAC (the Electronic Numerical Integrator and Computer). ENIAC was digital computer using the decimal (not binary) system, which could handle conditional branching and subroutines.
Incredible how much took place—or was at least initiated—over the course of a single year, and telling that the contributions that persisted were ones of collaboration, whether as partnerships of key individuals (e.g., Turing, Max Newman, and Alonzo Church) or in settings with collaborative resources (e.g., Bell Labs and major universities). Without diminishing their significance, those lone innovators were ultimately unable to mark history in the same way (e.g., Atanasoff, whose prototype was forgotten and dismantled, or Zuse, whose work with a single college friend was interrupted and lost when he was pulled into engineering airplanes for the German military).
As we head into this new year, I can only hope 2015 will be half as innovative as 1937, and that I can apply those lessons of collaboration to my blog and my continued growth as a developer.
]]><![CDATA[Should You Ever Edit Your Gemfile.lock? (No...But Maybe Sometimes...Conservatively)]]>2014-07-23T15:19:30+01:00http://cek.io/blog/2014/07/23/edit-gemfile-dot-lockWhen developing a Rails app, should you ever edit your Gemfile.lock? Easy answer: it’s no, right? Plentyofreputablesources all seem to discourage it. I myself gave that answer when asked recently. But I’ve come to learn that the answer is not a complete cut-and-dried “no”, at least not in certain circumstances.
Some background
How does the Gemfile work? A quick refresher:
The Gemfile is a list of all gems that you want to include in the project. It is used with bundler to install, update, remove and otherwise manage your used gems.
Bundler “provides a consistent environment for Ruby projects by tracking and installing the exact gems and versions that are needed. Bundler is an exit from dependency hell, and ensures that the gems you need are present in development, staging, and production. Starting work on a project is as simple as bundle install.”
Simply put, we list our gems and dependencies in the Gemfile, run bundle install, a Gemfile.lock is generated, and our dependencies are taken care of. Right?
What happens when we bundle install?
Quoting the bundler documentation:
Install the gems specified in your Gemfile. If this is the first time you run bundle install (and a Gemfile.lock does not exist), bundler will fetch all remote sources, resolve dependencies and install all needed gems.
If a Gemfile.lock does exist, and you have not updated your Gemfile, bundler will fetch all remote sources, but use the dependencies specified in the Gemfile.lock instead of resolving dependencies.
If a Gemfile.lock does exist, and you have updated your Gemfile, bundler will use the dependencies in the Gemfile.lock for all gems that you did not update, but will re-resolve the dependencies of gems that you did update.
No surprises here. This fits with the general understanding of Bundler and Gemfiles. But keep this in mind as you continue below, since the resolving of dependencies may mean more than you realize.
Introducing some controversy: conservative gem updates
Imagine this situation:
You run bundle update cucumber-rails, thinking it will only update cucumber-rails. In fact, this actually updates not just cucumber-rails, but all of its dependencies as well, which will explode in your face when one of these dependencies release a new version with breaking API changes. This happens all too often.
Lest you think I’m all alone in this, know that I’m pulling the above example from this post from Makandra Cards, and the idea in general from more experienced developers than myself. The author of the post suggests three options for conservative gem updates, the first of which is to make changes directly to Gemfile.lock.
Crazy, right? Controversial, even? Perhaps not. To date, Bundler has not acknowledged this issue, but there’s a significant use case (edge case, perhaps) that calls for editing Gemfile.lock. Just do it conservatively. Everything in moderation.
]]><![CDATA[Intro to JavaScript (According to Douglas Crockford)]]>2014-07-21T17:21:55+01:00http://cek.io/blog/2014/07/21/intro-to-javascript-crockfordSummary: I’m working my way through a few must-watch videos about JavaScript. If you know JavaScript, pretend to know JavaScript, or hope to learn JavaScript, check out those videos. Or read this and the previous post (and save yourself three hours of video-watching), in which I pull some of my favorite quotes from what Douglas Crockford has to say about JavaScript.
Notes: The quotes below represent some of the key statements (as I judge them) in order of their appearance in Crockford’s second talk on JavaScript. Read together, they outline the main trajectory of Crokford’s presentation, but they are not intended to replace the entirety of the talk.
Crockford on JavaScript’s key features
JavaScript: The Bad Parts
“Since I discovered that the language had good parts, that sort of implies that it must have had bad parts. Why would anybody design a language with bad parts? How would that come about? In my review of all the bad parts in the language, it mostly comes from three causes. The first is legacy. In copying the Java syntax, JavaScript also copied some bad things about Java, so many of the worst features in JavaScript are actually things it inherited from Java, which it inherited from C, which it inherited from FORTRAN. So there’s a long line of sin-age which affects us today.
“There were some good intentions in the language that didn’t quite work out. Things were added, like semi-colon insertion and implied global variables, with the intention of making the language easier to use for beginners. In fact, it worked, because it turns out that if you have absolutely no idea what you’re doing in the language you can still generally make things work. Unfortunately, those things work against professional programmers trying to do large, sophisticated programs, so there are some trade-offs there that didn’t work out well for us.
“But the biggest influence, by far, was haste. The language was designed, implemented, and shipped in way too little time. Most languages take years to develop – for example, Smalltalk was eight years from Alan Kay’s first prototype to Smalltalk 80, when it was first made available to the public. That’s a good timeframe for a programming language, because you want to go through it and test it, make sure that it works, and refine it in order to make sure that it’s meeting its goals. JavaScript was prepared in about as many days.” (Link)
JavaScript: The Good Parts
“The good news is that, for the most part, the bad parts can be avoided. And if you avoid the bad parts, and if you work just with what’s left over, the good parts, there’s actually a brilliant language there. The features that were selected and the way that they were put together is astonishingly good. It’s a language of amazing expressive power. JavaScript is a language that most people don’t bother to learn before they use. You can’t do that with any other language, and you shouldn’t want to, and you shouldn’t do that with this language either. Programming is a serious business, and you should have good knowledge about what you’re doing, but most people feel that they ought to be able to program in this language without any knowledge at all, and it still works. It’s because the language has enormous expressive power, and that’s not by accident. There’s actually some brilliant design in there.
“The problem with the bad parts isn’t that they’re useless, it’s that they’re dangerous. I see a lot of wannabe ninjas out there who are going through the bad parts and going ‘oh, I found a new use for with, or another thing you can do with eval,’ or some other edge case. Stop doing that. Stop doing that!” (Link)
Object-Oriented JavaScript
“This language is all about objects; it’s an object oriented language. I’ll try to demonstrate to you that it is more object oriented than Java. For a long time, a lot of the opinion about this language was that it’s not object oriented, it’s object based, it’s deficient. It turns out it’s actually a superior language.
“In this language, an object is a dynamic collection of properties. This is quite different than in most of the other object oriented languages in which an object is an instance of a class, where a class has some state and behavior. Objects in this system are much more dynamic. So it’s a collection of properties, and each property has a keystring which is unique within that object. If you add two properties with the same name, the second one will replace the first one.” (Link)
JavaScript accessor property (getter/setter)
“Here’s an example of using an accessor property. The difference between an accessor property and a data property is that an accessor property uses get and/or set. Here I’m defining a property for my object called inch. When I try to get inch, my_object, ’Inch’, I will receive the result of dividing this.mm by 25.4. If I try to set it, I won’t actually set this property, instead I will set millimeter to whatever value I pass times 25.4. So the result of this is that I can have an object with two properties in it that are linked in an interesting constraint way. I can set either the millimeters or the inch and it will appear to fix the other one, so I can keep those two things in sync. There are a lot of really interesting patterns that can be done with these. There are even more evil patterns that can be done with this.
“For example, one of the assumptions that you’ve always had in the language was that you can go to an object and retrieve a property and there’s no transfer of control, you’re just getting some data. Now you’re giving control over to a function which you hope will give it back, but it might not. But it can also mutate the object while it’s getting the thing, so something that used to be a read-only event is now potentially a mutating event which could mutate this object or who-knows-what in the thing. So there are all sorts of really abusive patterns that can be made out of these getters and setters, and I recommend to all the ninjas: don’t get stupid with stuff, because it’s going to be really, really easy to get stupid with this stuff. I’m telling you, you can get stupid with this stuff, and you don’t need to do it. So be smart with this. Use it sparingly.” (Link)
“The most controversial feature of the language is the way it does inheritance, which is radically different than virtually all other modern languages. Most languages use classes – I call them ‘classical languages’ – JavaScript does not. JavaScript is class free. It uses prototypes. For people who are classically trained who look at the language, they go: well, this is deficient. You don’t have classes, how can you get anything done? How can you have any confidence that the structure of your program’s going to work? And they never get past that.
“But it turns out classes as we currently understand them were first formulated in 1967, in Simula. The prototypal school was developed about 20 years later, at Xerox Parc, by people who had intimate knowledge of Smalltalk, which was the first modern semi-popular object oriented programming language. The changes that they made were not made in ignorance; it was very well informed, changing, simplifying, and advancing the programming model. And what they did was they created, in my view, a vast improvement over the model that had come before.
“It’s possible that one demonstration of the greater power of the new thing is that, first off, code is smaller. If you’re writing to the prototypal model and you’re doing it correctly, your programs are a lot smaller. For one thing, you take out a lot of the silly redundancy, like ‘I’m creating a variable of this type named That Type, initialized with new That Type.’ You’re saying everything three times, and you tend not to do that in a prototypal language. But more than that, you can simulate the classical language in the prototypal language. You can’t do the other. Java is not powerful enough that you can write in a JavaScript style in Java; it’s just not good enough. JavaScript is, so you can do it the other way around, because it’s the more powerful of the models.” (Link)
Object.create (don’t use new)
“I don’t use new anymore. I don’t need it. I’m thinking prototypally now, and when I’m thinking prototypally I can do everything I want to do with object.create. So I see this now as just a vestige; I don’t need it anymore. There’s also a hazard with new, that if you design a constructor that’s supposed to be used with new and either you, or one of your users, forgets to put the new prefix on it, instead of initializing a new object the instructor’s going to be clobbering the global object, damaging global variables and not doing useful work at all, and there’s no compile time warning or runtime warning of that. That’s a feature I don’t need to use.” (Link)
Functions and objects
“The best feature in the language, the good parts, the very best parts, are functions. We’ll talk about them next time. So that’s all the objects. All the values in this language are objects, with two exceptions: null, and undefined.” (Link)
JavaScript and C
“Syntactically, JavaScript is clearly a member of the C family of programming languages. It’s got the curly braces and all of that stuff. It differs from C mainly in its type system, which allows functions to be values.” (Link)
]]><![CDATA[JavaScript's Historical Context (According to Douglas Crockford)]]>2014-07-21T15:01:39+01:00http://cek.io/blog/2014/07/21/javascripts-historical-context-crockfordSummary: I’m working my way through a few must-watch videos about JavaScript. If you know JavaScript, pretend to know JavaScript, or hope to learn JavaScript, check out those videos. Or read this and the following post (and save yourself three hours of video-watching), in which I pull some of my favorite quotes from what Douglas Crockford has to say about JavaScript.
Notes: The quotes below represent some of the key statements (as I judge them) in order of their appearance in Crockford’s first and second talks on JavaScript. Read together, they outline the main trajectory of Crokford’s presentation, but they are not intended to replace the entirety of the talk. The first 50 minutes of the first talk, which cover the history of programming before 1970, are excluded from this post, not because they’re unimportant (they are!), but because it was difficult to pull single quotes that represented the content. All emphases mine.
Crockford on JavaScript’s historical context, distilled into key quotes
Innovation since the ‘70s
“The other thing we’ve seen is an end to CPU innovation. We used to see a lot of really radical new designs happening all the time, but we don’t see that happening anymore. Basically we’ve got three architectures that we use for most of our stuff: virtually all the computers are on Intel, most of the game platforms are on Power PCs, most of the mobile devices are on ARM, and that’s it. Nobody’s making new stuff, nothing radical, it’s just refinements of stuff that’s been happening for several decades.
“We’re doing even worse in operating systems. It used to be that every model of every machine had its own operating system, and that came with a lot of obvious inefficiency, so we’ve pushed that down and now we have just two: we’ve got Unix which was developed in the ‘70s, and we’ve got Windows that was developed in the ’80s. Of the two, Unix is obviously the better one, but there’s no innovation happening in operating systems. Basically we’ve been rewriting the same systems for 40 years. That’s just not where we do innovation. Where we do innovation is in programming languages, and that’s been going on for quite a long time.” (link)
Leaps
“Software development comes in leaps, and our leaps are much farther apart than the hardware experiences. Moore’s Law lets the hardware leap every two years; we leap more like every twenty years. Again, basically we need a generation to retire before we can get the good new ideas going, so despite the fact that we’re always talking about innovation and how we love innovation and we’re always innovating, we tend to be extremely conservative in the way we adopt new technology.” (Link)
The beginning of JavaScript
“Basically, [Brendan Eich] took these components: he took the syntax of Java, he took the function model of Scheme—which was brilliant, one of the best ideas in the history of programming languages—and he took the prototype objects from Self. He put them together in a really interesting way, really fast; he completed the whole thing in a couple of weeks. It’s a shame that he wasn’t given the freedom that Xerox had to spend a decade to get this right. Instead of ten years it was more like ten days, and that was it. I challenge any language designer to come up with a brand new design from scratch in ten days and then release it to the world and call it done and see what happens with that.
“One of the consequences of it was that there are parts of it that are just awful. If they’d had more time they probably would have recognized that and fixed it, but they didn’t. Netscape was not a company that had time to get it right, which is why there’s no longer a Netscape.
“But despite that, there is absolutely deep profound brilliance in this language, and this language is succeeding in places where many other languages have failed because of that brilliance; it’s not accidental that JavaScript has become the most popular programming language in the world.” (Link)
A great time to be a programmer
“One thing that’s different now than in the ‘50s and ’60s is there are lot of computers out there, and there are a lot of people writing programs now. It’s possible to get a community of people even if you have a minor language, enough to do useful things, to do a lot of group work. You’ve got a group large enough to justify writing books, which was something we didn’t have back in the ’50s and ’60s. So I think this is a great time to be a programmer. We have lots of choices, and we need to be smart about making those choices and be open to accepting the new ideas, because there are a lot of new ideas out there that we shouldn’t be rejecting just because they’re unfamiliar and we don’t see the need for them. There are actually a lot of good ideas in all of these languages, not least of which is JavaScript…” (Link)
Mythology of innovation
“Now, if you were here last time you’ll remember I went through the history of everything that ever happened, starting with The Big Bang, going through The Dawn of Man, and then finally there was JavaScript. The reason I did that was because understanding the context in which this stuff happens is really important to understanding what we have now. Without that understanding you’re consumed by mythology which has no truth in it, that the history of innovation has been one thing after another where the new, good thing always displaces the old stuff. That’s not how it works, generally. Generally the most important new innovations are received with contempt and horror and are accepted very slowly, if ever. That’s an important bit of knowledge to have, in the case of JavaScript.” (Link)
JavaScript has good parts
“Having that background [understanding history and innovation] allowed me to make the first important discovery of the 21st century, which was that JavaScript has good parts. This was an unexpected discovery, and when I tried to share it with the rest of the community there was a huge amount of skepticism; a lot of people refused to believe it was possible that JavaScript had any redeeming value whatsoever. In fact, it has very, very good parts. But I’m getting a little ahead of the story, so let’s back up a little bit.” (Link)
Why it’s called JavaScript (Netscape-Sun history)
“It was very clear at the time that there was a lot of excitement about Java and the Netscape browser, and Sun and Netscape decided they needed to work together against Microsoft because if they didn’t join forces Microsoft would play them off against each other and they’d both lose. The biggest point of contention in that arrangement was what to do with LiveScript. Sun’s position was: “Well, we’ll put Java into the Netscape browser, we’ll kill LiveScript, and that’ll be that.” And Netscape said no, that they really believed in the HyperCard-like functionality, and they wanted a simpler programming model in order to capture a much larger group of programmers.
“So there was an impasse, and the relationship almost broke up, when I think Marc Andreessen—and I have been able to document this, but people have told me—Marc Andreessen, maybe as a joke, suggested: ‘let’s change the name to JavaScript.’ And it worked! Except that Sun claimed ownership of the trademark. Even though they had nothing to do with the language and they tried to kill the language, they said ‘we own the trademark, but we’ll give you a license to use the trademark’. Netscape said ‘great, an exclusive license, only we can call it JavaScript, that’s fine’.” (Link)
The destruction of Microsoft
“At Microsoft they’d been watching this with some alarm, particularly when folks at Netscape were saying that Netscape Navigator was going destroy Microsoft. Microsoft said ‘oh, we don’t want to be destroyed’. It turned out Netscape Navigator didn’t destroy Microsoft. In fact, the software that is going to destroy Microsoft is Windows Mobile.” (Link)
JavaScript naming confusion
“What should we call the language? There’s a lot of confusion. Some people still think that JavaScript, JScript, and ECMAScript are three different languages, and that’s not the case. It’s three silly names for one silly language. JavaScript isn’t actually an open name, which is surprising in that this is the language of the world’s biggest open system. It’s a trademark now of Oracle, and we don’t know what they’re going to do with that. We probably should call it ECMAScript, except it’s such an awful thing to call it.”